Cloudflare「Markdown for Agents」が示すAI対策の新常識—あなたのサイトはAIエージェントに読まれていますか?

目次
この記事の結論:AIエージェント最適化が「やるべきこと」になった5つの理由
Cloudflareが2026年2月に発表した「Markdown for Agents」は、単なる技術リリースではありません。私がこの発表を読んで強く感じたのは、AIエージェントに最適なフォーマットでコンテンツを届けることが、もはやテクニカルSEOの必須項目になったということです。以下の5つが要点です。
- HTMLからMarkdownへの変換で約80%のトークン削減が実現する — 同一ページでHTMLが約16,000トークン、Markdownが約3,000トークンという検証結果がCloudflare公式ブログで報告されている。AIエージェントが消費するコストとレイテンシに直結する差だ
- Content-Signalヘッダーで「AI利用ポリシー」を機械的に宣言できる —
ai-train=yes、search=yes、ai-input=yesといった指示をHTTPヘッダーで返すことで、サイト所有者がAI学習・検索利用の許可を明示できるようになった - robots.txtだけではAIエージェント制御に限界がある — AIエージェントはクローラーとは異なる挙動をとる。
Accept: text/markdownヘッダーによるコンテンツネゴシエーションという新しい層が登場した - AIクロークのリスクが現実の脅威になっている — Markdown用リクエストと通常リクエストで異なるコンテンツを返す「シャドウWeb」の実証実験が報告されており、セキュリティの新たな課題が生まれている
- Cloudflare以外のサイトでも「AI対応フォーマット」の実装は可能 — llms.txtの採用、APIエンドポイントの追加、構造化データの強化など、自社サーバーでも実行できる施策がある
以下では、各テーマをデータと実装手順を交えて解説します。
1. Cloudflare「Markdown for Agents」とは何か
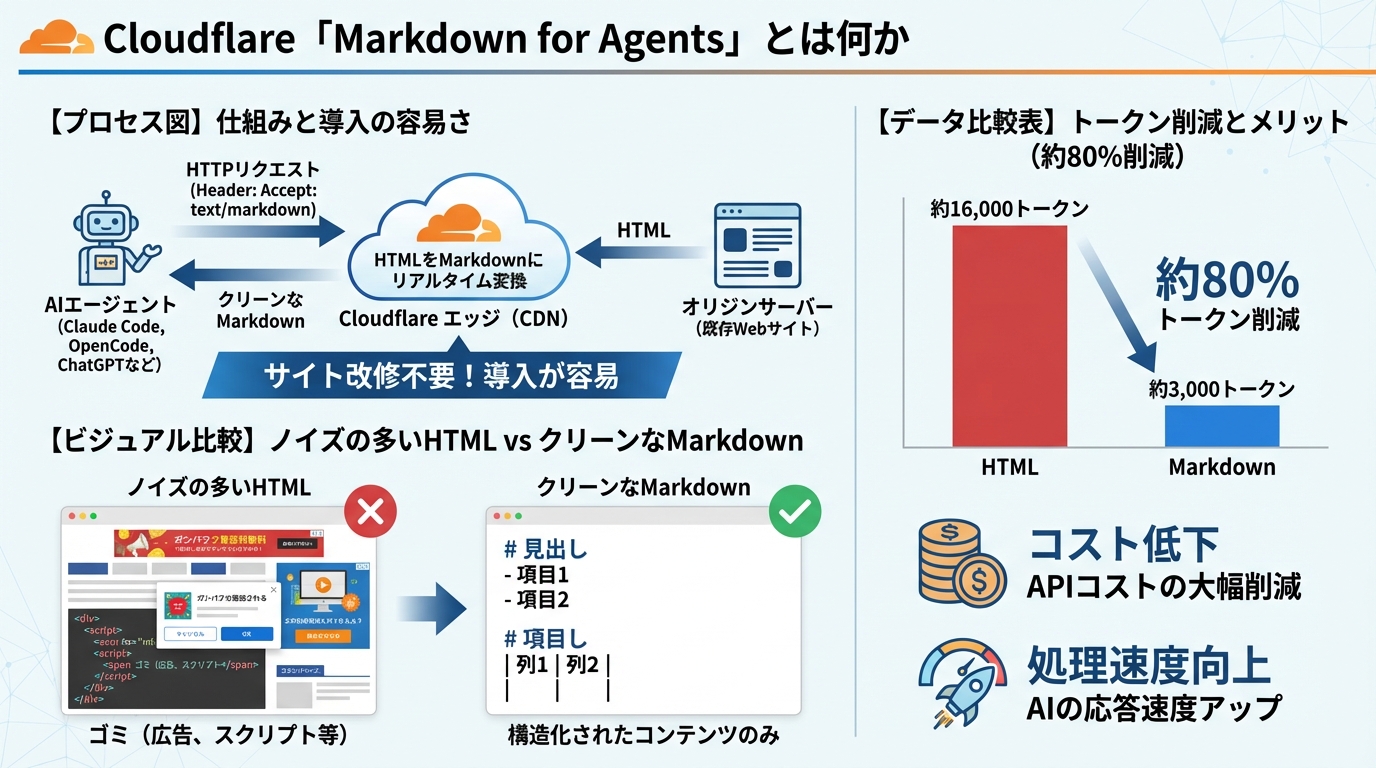
2026年2月、Cloudflareは「Markdown for Agents」を正式発表しました。一言で言えば、AIエージェントがWebページにアクセスしたとき、HTMLの代わりにMarkdown形式のコンテンツを返す仕組みです。
どう動くのか
AIエージェント(Claude Code、OpenCode、ChatGPTのブラウジング機能など)がHTTPリクエストに Accept: text/markdown ヘッダーを付与すると、CloudflareのCDNエッジがHTMLをリアルタイムでMarkdownに変換して返します。オリジンサーバーは通常通りHTMLを生成するだけでよく、サイト側のコード変更は不要です。
なぜMarkdownなのか
率直に言って、HTMLはAIにとって非常にノイズが多いフォーマットです。ナビゲーション、フッター、広告、JavaScript——AIが本当に必要とするのはメインコンテンツだけなのに、HTMLにはその何倍もの「ゴミ」が含まれています。
Markdownなら構造(見出し・リスト・表)を維持したまま、不要な要素を除去できます。Cloudflareの検証では、同一ページでHTMLが約16,000トークン、Markdownが約3,000トークン。約80%の削減です。
| フォーマット | トークン数(同一ページ) | 構造情報 | ノイズ |
|---|---|---|---|
| HTML | 約16,000 | 含む | 非常に多い |
| Markdown | 約3,000 | 含む | 最小限 |
| プレーンテキスト | 約2,500 | 失われる | 少ない |
参考・引用: Markdown for Agents - Cloudflare Blog Cloudflare Markdown for Agents - nohackspod Cloudflare Markdown for Agents - Thunderbit
2. 80%トークン削減の技術的インパクト
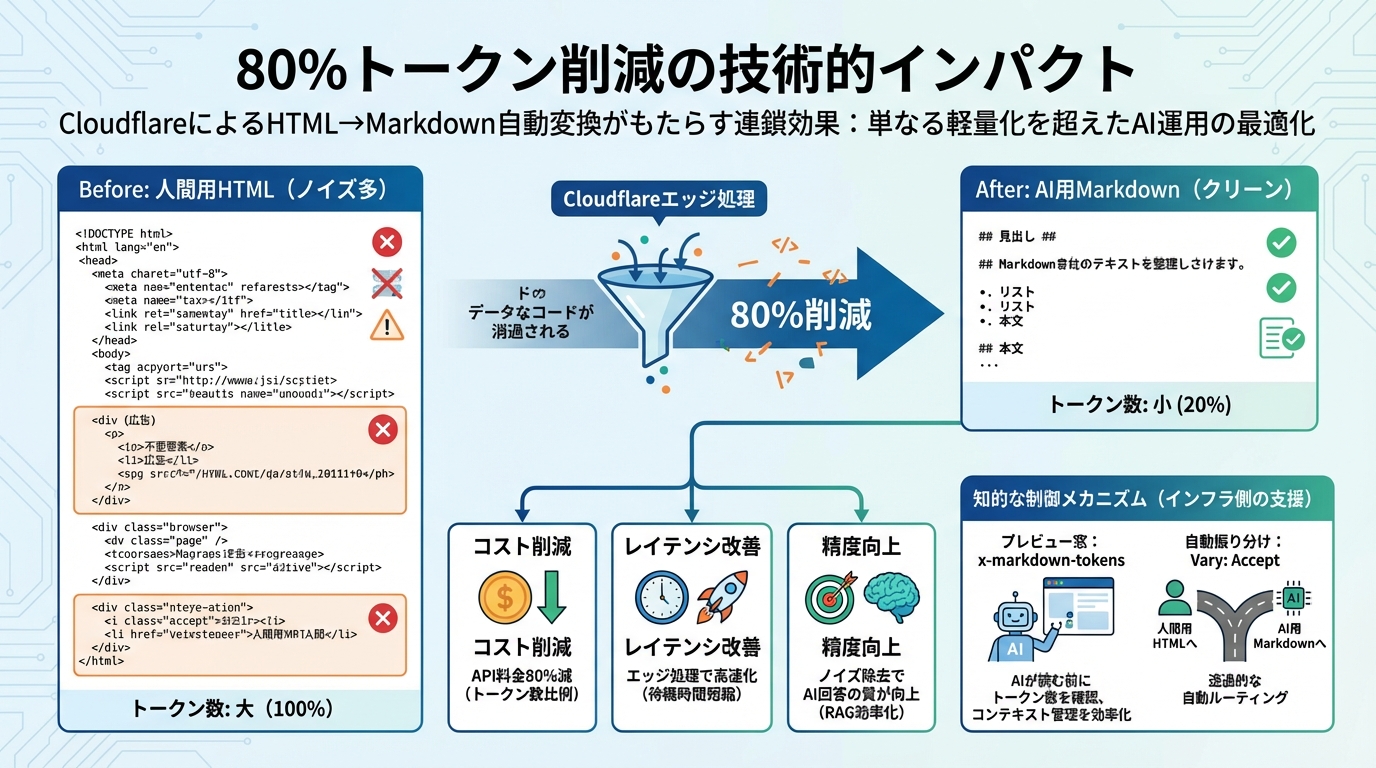
私がCloudflareの技術ドキュメントを読んで特に注目したのは、トークン削減がもたらす連鎖的な効果です。単に「軽くなる」だけではありません。
コスト・速度・精度の三重効果
コスト削減: LLMのAPI料金はトークン数に比例します。入力トークンが80%減れば、エージェントがページを読み込むコストも80%減です。大規模なRAG(Retrieval-Augmented Generation)システムでは、この差は月額の運用コストに直結します。
レイテンシ改善: 転送データ量が数分の一になるため、ネットワークのラウンドトリップタイムが短縮されます。特にエッジで変換が完了する点が重要で、オリジンサーバーへの追加負荷はゼロです。
精度向上: ノイズの少ないMarkdownを入力にすることで、AIの回答精度が向上します。HTMLのナビゲーションやフッターのテキストがコンテキストを汚染する問題が解消されるためです。
x-markdown-tokensヘッダー
Cloudflareのレスポンスには x-markdown-tokens ヘッダーが付与されます。AIエージェントはページを全文読み込む前にトークン数を把握できるため、コンテキストウィンドウの管理が格段に楽になります。
これは考えてみれば画期的です。従来、エージェントはページを取得してから「コンテキストに収まるか」を判断していました。事前にトークン数がわかれば、取得前にフィルタリングできます。
キャッシュの分離
Vary: Accept ヘッダーにより、HTML版とMarkdown版のキャッシュが自動的に分離されます。人間のブラウザにはHTML、AIエージェントにはMarkdownが返る——この使い分けがCDNレベルで透過的に行われます。
参考・引用: Markdown for Agents - Cloudflare Developers Cloudflare Now Converts Web Pages to Markdown - MediaCopilot Cloudflare Markdown for Agents - Search Engine Land
3. Content-Signalヘッダーとプライバシーの新しい課題
データを見ると、Markdownの技術的メリットは明確です。しかし、この技術にはセキュリティとプライバシーの両面で新たな課題が伴います。
Content-Signal:AIへの「利用許可証」
Cloudflareは Content-Signal というHTTPヘッダーを導入しました。サイト所有者が以下の3つの利用許可を機械可読で宣言できます。
ai-train=yes/no— AI学習データとしての利用を許可/拒否search=yes/no— 検索エンジンでの利用を許可/拒否ai-input=yes/no— AIへのリアルタイム入力としての利用を許可/拒否
robots.txtが「クローラーのアクセス制御」だったのに対し、Content-Signalは「コンテンツの利用目的の制御」です。GDPR・HIPAAなどの規制に合わせて、学習利用とリアルタイム応答利用を分離できる点は、特にエンタープライズにとって大きな意味を持ちます。
AIクロークのリスク
一方で、Accept: text/markdown ヘッダーの存在が新たな脅威を生んでいます。
実証実験では、AIエージェント向けリクエストに対して人間向けとは異なるコンテンツを返す「クローク」が容易に成立することが確認されています。たとえば、人間には正確な商品情報を見せながら、AIエージェントには競合他社の誤情報を含むコンテンツを返す——といった攻撃が技術的に可能です。
これはGoogleがかつて検索エンジン向けクロークをスパムとして取り締まった構図と同じです。AIエージェント向けの「シャドウWeb」が、今後のセキュリティ上の重要課題になるでしょう。
対策:ゼロトラストとCI検証
Cloudflare自身も、AI Security Suiteでゼロトラストポリシーの適用、リアルタイム監査ログ、プロンプトインジェクション防止を提供しています。サイト運営者としては、HTML版とMarkdown版のコンテンツに差異がないことをCIパイプラインで検証する習慣が必要です。
参考・引用: Cloudflare Markdown for Agents - QueryBurst Secure & Govern AI Agents - Cloudflare HackerNews Discussion on AI Cloaking Risks
LinkSurge
linksurge.jp
SEO・AIO・GEO統合分析プラットフォーム。AI Overviews分析、SEO順位計測、GEO引用最適化など、生成AI時代のブランド露出を最大化するための分析ツールを提供しています。
4. Cloudflareを使わなくてもできる「AI対応」施策
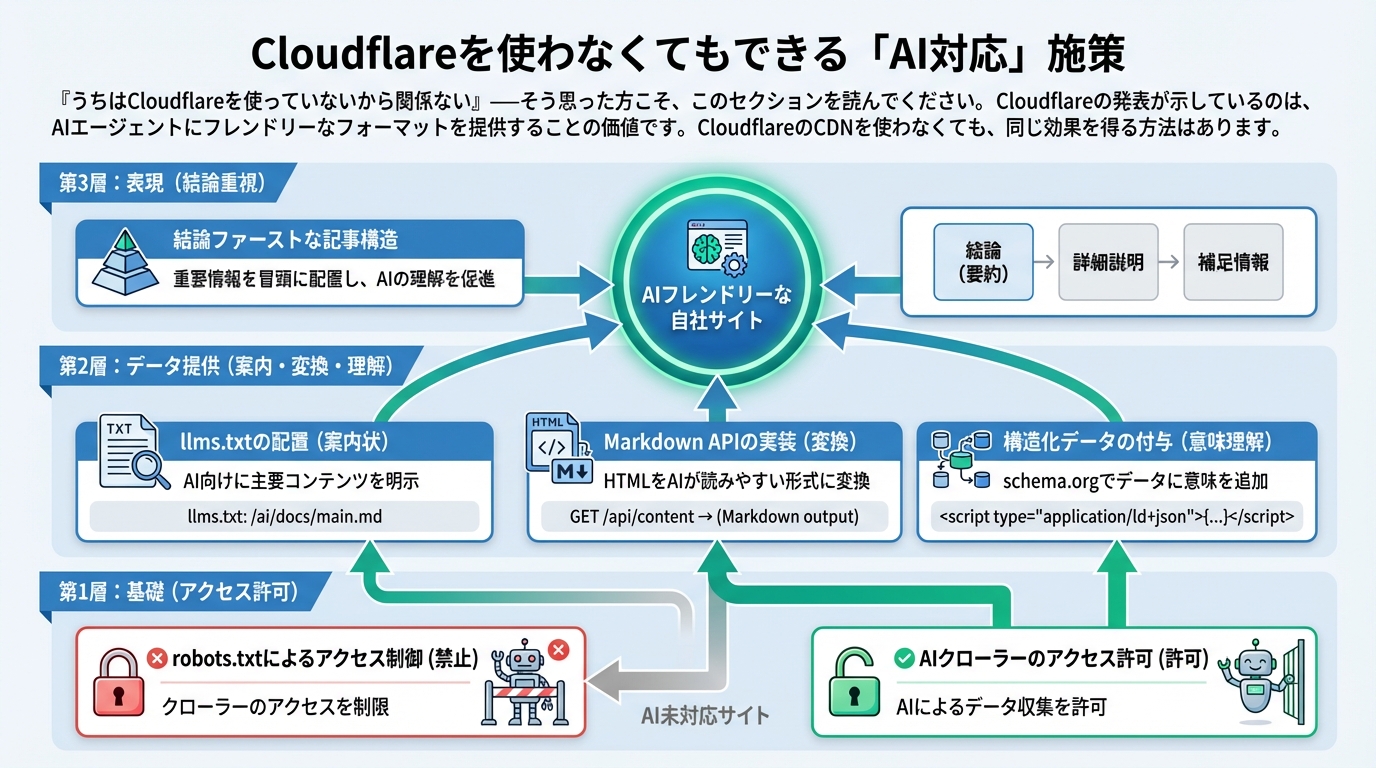
「うちはCloudflareを使っていないから関係ない」——そう思った方こそ、このセクションを読んでください。Cloudflareの発表が示しているのは、AIエージェントにフレンドリーなフォーマットを提供することの価値です。CloudflareのCDNを使わなくても、同じ効果を得る方法はあります。
施策1:llms.txtの導入
llms.txtは、サイトのルートに配置するテキストファイルで、AIエージェントにサイト構造やコンテンツの要約を提供する新しい標準です。robots.txtがクローラー向けの「立入禁止マップ」なら、llms.txtはAIエージェント向けの「案内パンフレット」です。
施策2:Markdown APIエンドポイントの追加
自社サーバーに /api/markdown?url=/blog/your-article/ のようなエンドポイントを用意し、Accept: text/markdown リクエストに対してMarkdown版コンテンツを返す実装が可能です。静的サイトジェネレーターを使っている場合、ソースのMarkdownファイルをそのまま配信する方法もあります。
施策3:構造化データの徹底
JSON-LD(Article、FAQPage、HowTo)の実装は、AIがコンテンツの意味と構造を理解するための最も確実な方法です。Cloudflareの変換はあくまで「HTMLをMarkdownに変える」処理であり、構造化データが持つセマンティック情報はそもそもMarkdownでは表現できません。つまり、構造化データはMarkdown変換とは別の層で必要です。
施策4:AIクローラーのアクセス許可
robots.txtで主要なAIクローラー(GPTBot、PerplexityBot、ClaudeBot)へのアクセスを明示的に許可し、サイトマップを定期更新してAIが情報を取得しやすい環境を整備します。
AIクローラーへの対応とサイト構造の最適化については「生成AI検索がSEOを変える:7つの実践対策」で詳しく解説しています。
施策5:コンテンツの「結論ファースト」構造化
AIが回答を生成する際、セクション冒頭の40〜60語を優先的に参照します。各セクションの冒頭に結論を配置する「Atomic Answers」形式は、Markdownフォーマットの提供と同等以上にAI引用率を高める施策です。
GEOの技術実装やプラットフォーム別の引用戦略については「GEO完全ガイド」で体系的にまとめています。
参考・引用: How to Serve Markdown to AI Agents - dev.to Cloudflare The Secret Weapon for Building AI Agents - JustThink AI Don't Let Your AI Agents Go Rogue - Softprom
5. 今すぐ始めるAIエージェント最適化ロードマップ
施策の優先順位が見えてきたところで、具体的な実行順序を整理します。
フェーズ0:現状把握(1日)
- 自社サイトを
curl -H "Accept: text/markdown"でリクエストし、何が返るか確認する - LinkSurgeのAI Overview分析で、自社コンテンツがAIにどう引用されているか把握する
- robots.txtでAIクローラーがブロックされていないか確認する
フェーズ1:構造化データの実装(1〜2週間)
- FAQPage、Article、HowToのJSON-LDを主要ページに追加
- 各セクション冒頭に40〜60語のAtomic Answersを配置
- sitemap.xmlを更新し、AIクローラーが全ページにアクセスできるようにする
フェーズ2:機械可読フォーマットの提供(2〜4週間)
- llms.txtファイルの作成と配置
- Markdown APIエンドポイントの実装(技術リソースがある場合)
- Content-Signal相当のメタタグまたはHTTPヘッダーの追加
フェーズ3:計測と改善(継続)
- AI引用率の定期モニタリング(LinkSurgeのAI Overview分析)
x-markdown-tokensに相当するトークン効率の検証- 新規AIクローラーへの対応(User-Agentの追加許可)
SEO・コンテンツ・リンク構築を含む包括的な戦略については「2026年最新 SEO対策完全ガイド」を参照してください。
参考・引用: Best Practices SASE for AI - Cloudflare Blog Markdown for Agents - Cloudflare Developers Cloudflare Markdown for Agents - Search Engine Land
よくある質問(FAQ)
Cloudflare「Markdown for Agents」はどのプランで使えますか?
Pro、Business、Enterpriseプランで利用可能です。ダッシュボードの「Bots/AI」セクションからワンクリックで有効化できます。APIでの有効化も可能で、PATCH /client/v4/zones/{zone_tag}/settings/content_converter エンドポイントを使用します。Freeプランでは利用できません。
Cloudflareを使っていないサイトでもAIエージェント対応は可能ですか?
可能です。llms.txtの配置、Markdown APIエンドポイントの追加、JSON-LDの実装、AIクローラーへのrobots.txt許可など、自社サーバーで実行できる施策が複数あります。Cloudflareのサービスはこれらを自動化するものですが、手動実装でも同等の効果が得られます。
Content-Signalヘッダーとrobots.txtの違いは何ですか?
robots.txtはクローラーの「アクセス」を制御するファイルです。一方、Content-Signalはアクセスを許可した上で「コンテンツの利用目的」を制御するHTTPヘッダーです。たとえば、ページへのアクセスは許可しつつ、AI学習データとしての利用は拒否する、といった細かい制御が可能になります。
AIクロークとは何ですか?対策はありますか?
AIエージェント向けリクエスト(Accept: text/markdown)に対して、人間向けとは異なるコンテンツを返すことをAIクロークと呼びます。検索エンジン向けクロークと同様、意図的な誤情報配信や操作に悪用される可能性があります。対策としては、HTML版とMarkdown版のコンテンツ一致をCIパイプラインで自動検証すること、Cloudflare AI Security Suiteのようなゼロトラストポリシーの適用が有効です。
まとめ:AIエージェント対応は「技術SEO」の新しい必須項目
Cloudflareの「Markdown for Agents」は、Web全体がAIエージェントとの対話に適応し始めたことを象徴する動きです。
まず取り組むべきは3つです。構造化データの実装、AIクローラーへのアクセス許可、そして結論ファースト構造のコンテンツ設計。Cloudflareを使うかどうかに関係なく、これらの施策でAIエージェントからの引用確率を高められます。
LinkSurgeのAI Overview分析機能では、自社コンテンツがAI検索でどのように引用されているかをリアルタイムで確認できます。AIエージェント対応の効果測定にお役立てください。


