生成エンジン最適化(GEO)完全ガイド:ChatGPT・Gemini・PerplexityにAI引用される実践手法【2026年日本版】

目次
この記事の結論:GEOで成果を出す5つの要点
2026年、コンテンツマーケティングの勝敗は「検索結果に表示される」ことだけでなく、「AIに引用される」かどうかで決まります。私がこの半年間、ChatGPT・Perplexity・Claudeの引用パターンを調査してきた結果、プラットフォームごとに最適化の勘所が明確に違うことがわかりました。GEO(Generative Engine Optimization)は、これらの生成AIが回答に自社コンテンツを採用・引用する確率を高める最適化手法です。以下の5つが実践上の要点です。
- 構造化データとPromptフレンドリーな文章設計が引用の土台 — JSON-LDでFAQPage・Article・Productスキーマを実装し、各セクション冒頭40〜50語に結論を配置することで、RAG(Retrieval-Augmented Generation)が情報を正確に取得・引用しやすくなる
- プラットフォームごとに引用メカニズムが異なる — ChatGPTはブラウジング+OAI-SearchBot、GeminiはKnowledge Graph連携、PerplexityはSourcesリスト、ClaudeはCitation APIと、各エンジンの引用方式に合わせた最適化が必要になる
- 日本語特有の形態素処理と敬語表現がAI引用に影響する — 日本語は形態素単位でトークン化されるため、1文30〜50トークンに収まる短文設計が有効。敬語表現を自然に含めるとClaudeの引用精度が向上する
- 日本の法制度(著作権法・APPI)への準拠が不可欠 — AI学習段階は情報解析として原則許諾不要だが、生成・利用段階では著作権侵害リスクがある。個人情報保護法(APPI)に基づくデータマスキングも必須になる
- Citation Rateを中心としたKPI設計と段階的実行が成功の鍵 — AIが生成した回答に自社URLが出現する割合を計測し、5フェーズの実行プランで段階的に導入・改善する
以下では、各テーマを技術的な実装方法と日本国内の法制度を踏まえて順に解説します。
1. GEOとは何か — 定義・仕組み・SEOとの違い
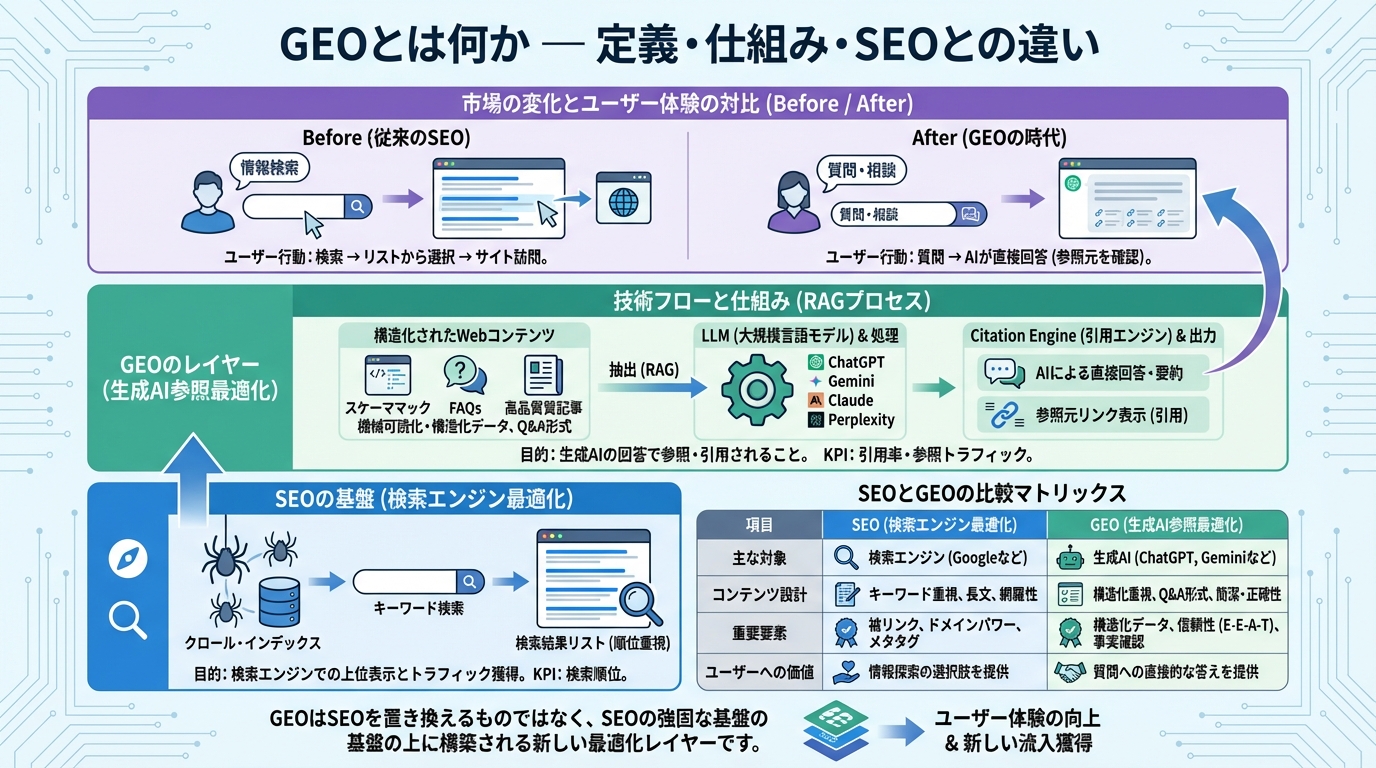
GEOの定義
GEO(Generative Engine Optimization)とは、ChatGPT、Google Gemini、Perplexity、Anthropic Claudeなどの生成AIがユーザーの質問に対して直接回答や要約を生成する際に、参照・引用されやすいようにコンテンツを機械可読化・構造化する最適化手法です。
SEOが検索結果での順位を高めることに重点を置くのに対し、GEOは「AIが回答に採用・引用する確率」を高めることが目的です。
なぜGEOが必要なのか
これは私が最近のクライアント案件で痛感していることですが、ゼロクリック検索の急増により、ユーザーはAIの回答で情報を完結させる傾向が強まっています。AI Overviews表示時のオーガニックCTRは50〜60%低下するとの調査結果が出ています(Ahrefs, 2025年12月;Seer Interactive, 2025年11月)。従来のSEOだけでは流入を維持できなくなりつつあります。AI OverviewsやAI Modeが日本のSEOに与える影響と具体的な対策は「生成AI検索がSEOを変える:7つの実践対策」で詳しく解説しています。GEOは、この新しい検索環境でブランドの可視性を確保するための戦略です。
GEOを支える2つの技術基盤
GEOを理解するには、AIが回答を生成する2つの仕組みを知る必要があります。
RAG(Retrieval-Augmented Generation) は、検索エンジンや外部データベースから取得した情報をリアルタイムでLLMに注入し、回答を生成する技術です。AIは学習データだけでなく、検索時に取得した最新情報を組み合わせて回答します。GEOの技術的最適化は、このRAGパイプラインで自社コンテンツが優先的に取得されることを目指します。
Citation Engine は、AIが生成した回答に対し、根拠となるURLや文献情報を自動的に添付する機構です。ChatGPTのブラウジング、Perplexityの「Sources」タブ、ClaudeのCitation API、Google AI Overviewの出典リストがこれに該当します。Citation Engineに認識されることが、GEOの最終的なゴールです。
| 項目 | SEO | GEO |
|---|---|---|
| 最適化対象 | 検索エンジンの順位アルゴリズム | 生成AIのRAG + Citation Engine |
| 主要KPI | キーワード順位、オーガニックCTR | Citation Rate、Share of Synthesis |
| コンテンツ設計 | キーワード密度、被リンク | 機械可読化、構造化データ、Q&A形式 |
| 成果の現れ方 | 検索結果ページに表示 | AIの回答に引用・出典として表示 |
SEOの技術基盤・コンテンツ戦略・リンク構築・実装ロードマップについては「2026年最新 SEO対策完全ガイド」で包括的に解説しています。GEOはSEOの上に構築する戦略であり、SEOの基盤が整っていることが前提です。
参考・引用: Generative Engine Optimization - CrafterCMS GEO vs Traditional SEO Guide - Strapi How AI Engines Cite Sources - Medium
2. AIに引用される技術的最適化テクニック
GEOの全体像を押さえたところで、次は具体的な技術実装に入ります。AIに引用されるコンテンツを作るには、6つの技術的な実装ポイントがあります。
構造化データ(JSON-LD)の実装
schema.orgに準拠したJSON-LDマークアップは、AIがコンテンツの意味を正確に理解するための基盤です。FAQPage、Article、Product、HowToなどのタイプを明示することで、RAGが情報を構造的に取得しやすくなります。
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "FAQPage", "mainEntity": [{ "name": "GEOとは何ですか?", "acceptedAnswer": { "text": "GEOは生成AIに引用されるためのコンテンツ最適化手法です。" } }] } </script>
Promptフレンドリーな文章設計
私が実際にPerplexityとClaudeで検証した限り、セクション冒頭に結論がある記事とない記事では引用のされ方が明確に違います。各セクションの冒頭40〜50語に結論・キーワードを配置し、見出しをQ&A形式にします。AIは回答生成時にセクション冒頭を優先的に参照するため、「結論ファースト」の構造が引用確率を大きく左右します。
コンテンツチャンクの分割
800トークン以内のブロックに分割し、各ブロックに固有の見出しとURLアンカーを付与します。RAGは長文をそのまま処理するよりも、適切に分割されたチャンクを取得する方が精度が高くなります。
埋め込みベクトルの最適化
テキストをSentence-Transformerなどのモデルでベクトル化し、FAISSなどのベクトルDBに格納すると、検索時に類似度の高いチャンクがRAGに供給されます。自社でRAGパイプラインを構築する場合に特に有効です。
URL設計とAIクローラー制御
正規化されたクリーンURL、canonical設定、robots.txtでの GPTBot や PerplexityBot の許可・除外を明示します。AIに引用されたいページは明確に許可し、引用されたくないページは除外する制御が必要です。
robots.txtに加えて、Cloudflareの「Markdown for Agents」のようなAIエージェント向けフォーマット提供も有効な施策です。Content-Signalヘッダーによる利用目的の制御など、最新のAI対応手法については「Cloudflare Markdown for AgentsとAI対策の新常識」で解説しています。
キャッシュ制御
頻繁に更新されない情報は Cache-Control: max-age=86400 で長期キャッシュし、最新情報は no-cache に設定します。APIで提供するデータは ETag との併用が推奨されます。
| 施策 | 優先度 | 実装難易度 | AI引用への効果 |
|---|---|---|---|
| JSON-LD構造化データ | 最高 | 中 | 直接的にAI引用率を向上 |
| Promptフレンドリー文章 | 最高 | 低 | 冒頭配置で引用確率が大幅向上 |
| コンテンツチャンク分割 | 高 | 低 | RAG取得精度の向上 |
| ベクトル埋め込み最適化 | 中 | 高 | 自社RAG構築時に有効 |
| AIクローラー制御 | 高 | 低 | 引用対象ページの明確化 |
| キャッシュ制御 | 中 | 低 | クロール効率の改善 |
参考・引用: 構造化データの概要 - Google Developers 生成AI時代のコンテンツ - Google Developers GEO vs Traditional SEO - Strapi
3. プラットフォーム別の引用戦略と連携方法
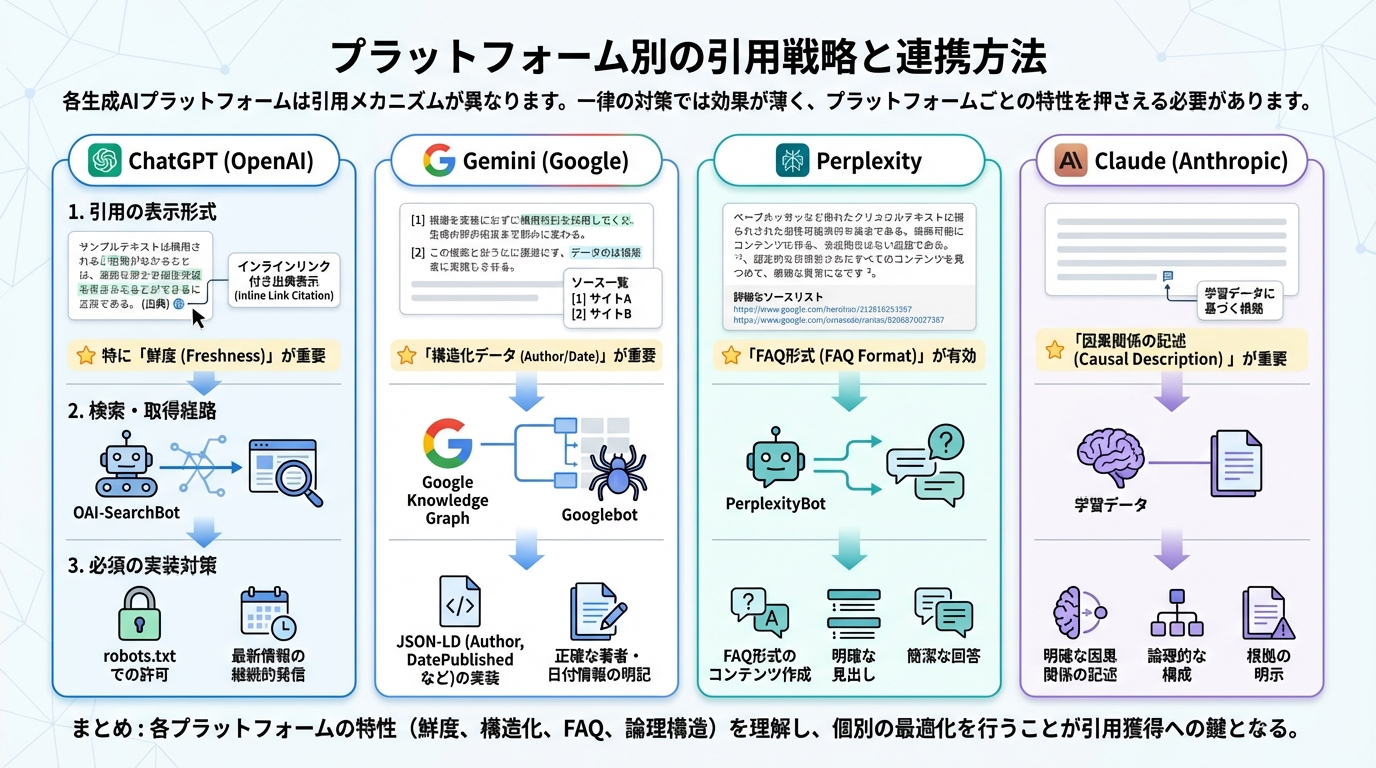
ここがGEOの中でも最も面白い部分です。各生成AIプラットフォームは引用メカニズムが異なります。一律の対策では効果が薄く、プラットフォームごとの特性を押さえる必要があります。
ChatGPT(OpenAI)
ChatGPTはブラウジングモードで取得したページをインラインリンク付きで出典表示します。検索にはOAI-SearchBotクローラーが使用されるため、robots.txtでの許可が必要です。なお、旧プラグインプログラムは2024年3月〜4月に段階的に廃止され(OpenAI Help Center)、後継はカスタムGPT + Actionsです。
具体的には以下を押さえます。
robots.txtでUser-agent: OAI-SearchBotを許可する- Bing・Google両方のインデックスに登録する(ChatGPTは複数の検索ソースを利用)
- 「最終更新日」をページ上に明示する(鮮度シグナルが強い)
- カスタムGPTのActionsで自社APIと連携する(旧プラグインの代替)
Google Gemini
Geminiは複雑なクエリを平均6〜10個のサブクエリに分解し、それぞれに最も権威のあるソースを取得します。このサブクエリ分解の仕組みは「クエリファンアウト」と呼ばれ、AI ModeやAI Overviewsの中核技術として機能しています(詳細は「クエリファンアウトとは?初心者向け解説」を参照)。Google SearchのKnowledge Graphに登録された sameAs、url、author などのプロパティが引用に反映されやすい特徴があります。APIレスポンスでは groundingMetadata.groundingChunks[].web.uri にソースURLが返されます。
- JSON-LDで
ArticleにauthorとdatePublishedを明示する - Google Cloud ConsoleからVertex AI経由でGemini APIキーを取得する
- マルチモーダルコンテンツ(画像・動画+schema)と週次更新で鮮度シグナルを維持する
Perplexity
Perplexityは回答下部に「Sources」リストを自動生成し、URLがクリック可能な形で表示されます。Quick Search(高速・簡易)とPro Search(深掘り・複数ソース)で出典の網羅性が異なります。
robots.txtにUser-agent: PerplexityBotの許可設定を追加する- FAQ形式(「Q. ○○は?」/「A. …」)で記述すると、QAペアとして認識されやすい
- 信頼性が高いと判断されたサイトが優先的に引用される
Anthropic Claude
ClaudeのCitation APIは、リクエスト内で提供されたドキュメントの特定箇所(文字位置やページ位置)を参照する構造化された引用ブロックを返します。外部URLを含むフットノートではなく、ドキュメント内の引用箇所を正確に特定する仕組みです。なお、CitationsとStructured Outputsは併用不可で、両方を有効にすると400エラーが返されます。Claude は日本語の自然言語処理精度が高く、論理的な因果関係の文章を引用しやすい特徴があります。
- ドキュメントブロックごとに
citations: {"enabled": true}を設定して引用を有効化する - 著者の専門性・権威性を明示するプロフィールを整備する
- if-then構造や因果関係を明示した文章設計で引用精度を高める
| プラットフォーム | 引用方式 | 最重要シグナル | 連携窓口 |
|---|---|---|---|
| ChatGPT | インラインリンク | 鮮度 + OAI-SearchBotクロール許可 | robots.txt + Bing/Googleインデックス |
| Gemini | groundingChunks[].web.uri + Knowledge Graph | JSON-LD author / datePublished | Google Cloud Console |
| Perplexity | Sourcesリスト(クリック可能) | robots.txt許可 + FAQ形式 | Developer APIページ |
| Claude | 構造化引用ブロック | 著者権威性 + 論理的因果関係 | Anthropic Console |
参考・引用: Overview of OpenAI crawlers - OpenAI Platform Grounding with Google Search - Gemini API Citations - Anthropic API Docs AI Overviews Everything You Need to Know - Search Engine Land
4. 日本語・文化適応のポイント
プラットフォーム別の戦略を理解したところで、次は日本市場ならではの最適化です。GEOを日本で実践するなら、日本語ならではの言語特性と文化的背景への対応は避けて通れません。驚いたのは、敬語表現の使い方がAI引用の精度に影響するという点です。
形態素処理とトークン化への対応
日本語は英語と異なり、形態素(単語の最小単位)でトークン化されます。1文が30〜50トークンに収まるように短くまとめることで、RAGが情報を正確にチャンク分割し、取得精度が向上します。長文の接続詞や修飾語を削り、主語と述語を近くに配置しましょう。
敬語・敬称の効果的な活用
「ご利用いただく」「お客様」などの敬語を自然にちりばめると、特にClaudeが高い信頼度で引用しやすくなります。ただし過度な敬語は逆効果です。「です・ます」調を基本とし、専門的な解説では「である」調を混ぜる使い分けが効果的です。
ローカライズされたメタデータの設定
HTMLの <head> に hreflang="ja"、language="ja"、locale="ja_JP" を追加し、検索エンジンとAIに日本語ページであることを明示します。多言語サイトではhreflang設定が正確でないと、AIが誤った言語版を引用する可能性があります。
文化的トピックとFAQスタイル
「和食」「温泉」「年末年始」など、季節性・地域性が強いキーワードはユーザーの検索意図と合致しやすく、AI引用の対象になりやすい傾向があります。Q&Aを「Q. ○○とは?」/「A. …」の形で記載すると、PerplexityとClaudeがquestion-answerペアと認識しやすくなります。
| 項目 | 注意点 | 具体的な実装 |
|---|---|---|
| 形態素・トークン化 | 1文30〜50トークンに収める | 接続詞・修飾語を削り、短文を意識 |
| 敬語・敬称 | 自然な敬語がClaudeの引用精度を向上 | 「です・ます」調を基本に、過度な敬語は避ける |
| メタデータ | hreflang / locale を正確に設定 | hreflang="ja"、locale="ja_JP" を <head> に追加 |
| 文化的トピック | 季節性・地域性キーワードが有効 | 「和食」「温泉」「年末年始」等を自然に含める |
| FAQスタイル | Q&A形式がAIの認識を助ける | 「Q. ○○とは?」/「A. …」で記述 |
参考・引用: GEO(Generative Engine Optimization) - 電通デジタル AI Overviews Guide - LANY Claude Code Guide — 多言語対応 - Zenn
LinkSurge
linksurge.jp
SEO・AIO・GEO統合分析プラットフォーム。AI Overviews分析、SEO順位計測、GEO引用最適化など、生成AI時代のブランド露出を最大化するための分析ツールを提供しています。
5. 日本の法的・規制・倫理コンテキスト
GEOを日本で実践する際、著作権法・個人情報保護法・AIガバナンスの3つの法的領域を理解しておく必要があります。
著作権法と情報解析の例外
AI学習段階は情報解析として「非享受利用」に該当し、著作権法第30条の4により原則として許諾不要と解釈されるのが一般的です(文化庁「AIと著作権に関する考え方について」, 2024年3月)。ただし生成・利用段階では通常の著作権が適用され、既存作品との「類似性」と「依拠性」が認められれば著作権侵害となる可能性があります。
GEOの文脈では、自社コンテンツがAIに引用されること自体は著作権上の問題になりにくいと考えられていますが、AI生成物が他社著作物と類似するリスクには注意が必要です。具体的な判断はケースにより異なるため、最終的な判断は法務確認を推奨します。
個人情報保護法(APPI)への準拠
個人情報保護法(APPI)では、個人情報を含むコンテンツの取得・保存・第三者提供時に利用目的の明示と本人同意が求められるのが原則です(個人情報保護法第17条・第23条)。AIが学習に使用する際は「利用目的が情報解析」に限定し、個人識別情報はマスクすることが推奨されます。
ベクトルDBに格納するデータに個人情報が含まれる場合、事前の匿名化・ハッシュ化処理が必要とされています。なお、APPIの解釈は個人情報保護委員会のガイドラインや事業分野により異なるため、最終的な判断は法務確認を推奨します。
AIガバナンスと透明性
経済産業省のAI原則ガイドラインは「透明性」「公平性」「安全性」「プライバシー」を要件としています。AIが生成したコンテンツに対しては出典表示と誤情報防止が求められ、公的機関が提供するデータは国内サーバでのホスティングが推奨されます。
| 領域 | 主なポイント | 実務での対応 |
|---|---|---|
| 著作権 | 学習段階は原則許諾不要とされる(第30条の4)。生成段階は類似性+依拠性で判断 | 生成物の類似性チェックツール導入。法務確認推奨 |
| 個人情報保護(APPI) | 個人情報のマスク・匿名化が原則必要 | ベクトル化前にPIIをハッシュ化/削除。法務確認推奨 |
| AIガバナンス | 透明性・出典表示・誤情報防止 | 出典表示ポリシーの文書化 |
| データローカリゼーション | 公的データは国内サーバで管理 | 外部転送時は事前同意取得 |
参考・引用: AIと著作権に関する考え方について - 文化庁 個人情報保護法 - 個人情報保護委員会 生成AIの著作権 - LegalOnTech AI原則ガイドライン - IPA
6. 計測・分析の指標とツール
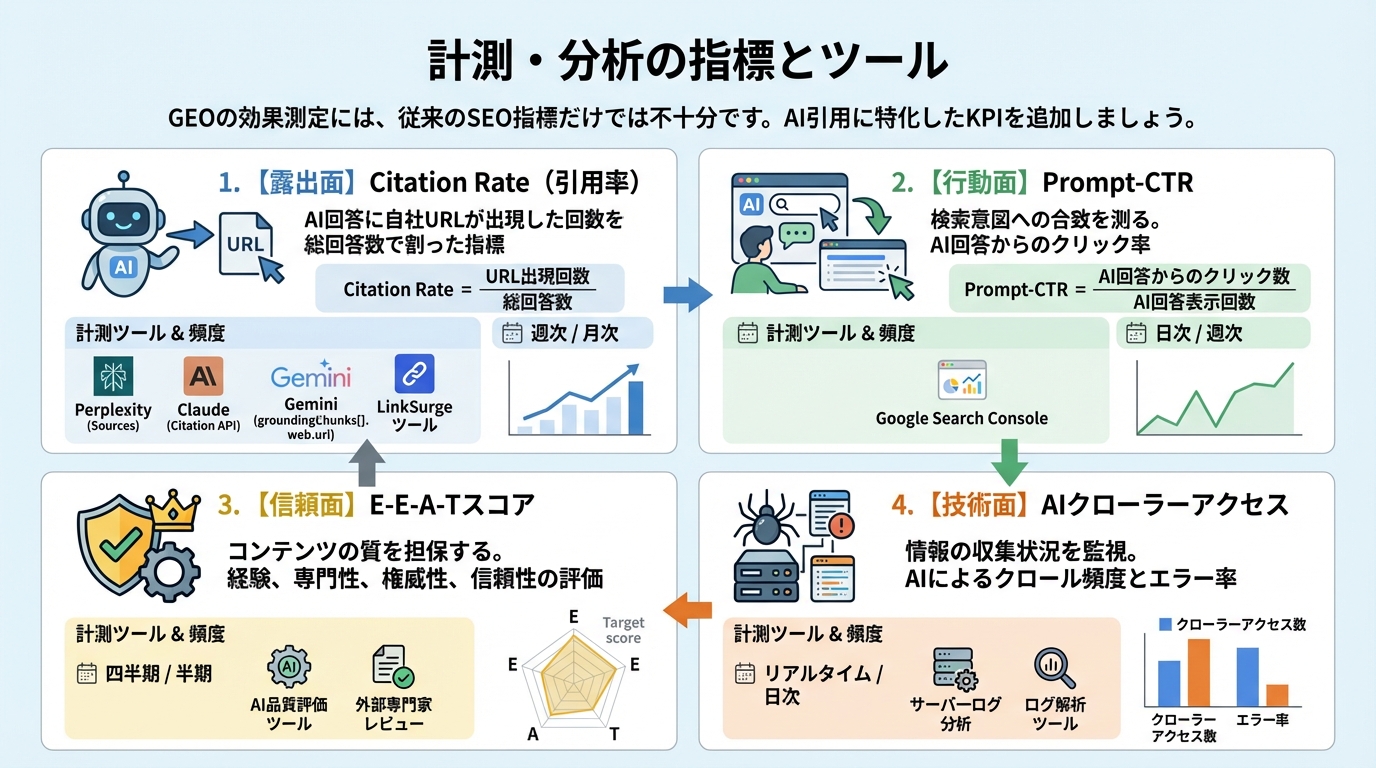
施策を実行するだけでは不十分で、効果測定の仕組みがなければ改善サイクルが回りません。GEOの効果測定には、従来のSEO指標だけでは不十分です。AI引用に特化したKPIを追加しましょう。
Citation Rate(引用率)
AIが生成した回答に自社URLが出現した回数を総回答数で割った指標です。Perplexityの「Sources」タブ、ClaudeのCitation API、Geminiの groundingChunks[].web.uri をログに集計して算出します。
GEOの最も基本的なKPIであり、月次で推移をトラッキングすることが推奨されます。LinkSurgeのAI Overview分析では、Google AI Overviewsでの引用状況をキーワード単位で確認できます。
Prompt-CTR(質問クリック率)
検索結果画面で「質問例」がクリックされた率です。Google Search Consoleの「パフォーマンス」→「クエリ」で質問形式のキーワードを抽出し、CTRを分析します。FAQ形式のコンテンツが検索ユーザーの意図に合致しているかを測定できます。
E-E-A-Tスコア
Googleの品質評価ガイドラインに基づく専門性・権威性・信頼性の内部評価です。構造化データの author、publisher、datePublished が評価対象になります。数値化が難しいため、チェックリスト形式での定期評価が実用的です。
AIクローラーアクセスのモニタリング
サーバーログで GPTBot、PerplexityBot、ClaudeBot のアクセス状況を監視します。robots.txtの設定が正しく機能しているか、AIクローラーがどのページを取得しているかを把握できます。
| 指標 | 測定方法 | 頻度 |
|---|---|---|
| Citation Rate | AI回答内の自社URL出現率を集計 | 月次 |
| Prompt-CTR | Search Console → 質問形式クエリのCTR | 週次 |
| E-E-A-Tスコア | チェックリスト形式の内部評価 | 四半期 |
| AIクローラーアクセス | サーバーログでBot別アクセス解析 | 週次 |
| APPIコンプライアンス | データ取得・保持ログの監査 | 四半期 |
参考・引用: How AI Engines Cite Sources - Medium Google Search品質評価ガイドライン - Google Developers Succeeding in AI Search - Google
7. 5フェーズ実行プラン
GEOの導入は一度にすべてを実装するのではなく、5つのフェーズに分けて段階的に進めることが効果的です。
フェーズ0:事前分析(1週間)
- 主要キーワード・質問リストの作成(日本語Q&A形式)
- 競合サイトのAI引用状況を調査(Perplexity / Claude で自社カテゴリを検索、LinkSurgeでAI Overview出現状況を分析)
- 現状のCitation Rateをベースライン測定
フェーズ1:技術基盤の構築(2週間)
- JSON-LDで
FAQPage・Articleを実装 hreflang="ja"とcanonicalの設定robots.txtにAIクローラー許可記述を追加- Core Web Vitalsの達成確認
フェーズ2:コンテンツ最適化(3週間)
- 既存ページの冒頭に40〜50語の要点文を配置
- Q&Aペアを各ページ5件以上作成
- 画像・動画に代替テキストを付与
- コンテンツを800トークン以内のチャンクに分割
フェーズ3:プラットフォーム連携(4週間)
- OAI-SearchBot / PerplexityBot のrobots.txt許可設定
- Gemini APIキー取得・テスト実装
- Perplexity API(Pro)で自社データベース接続
- 各プラットフォームでの引用テストを実施
フェーズ4:法務・計測・継続改善(継続)
- APPIに基づく個人情報マスク方針の策定
- 著作権リスクチェック(類似性・依拠性の定期確認)
- Citation Rateダッシュボードの構築(LinkSurgeのGEO分析機能で競合比較も可能)
- 月次のE-E-A-T評価と改善レポート
8. リスクと対策
GEO導入にはリスクもあります。事前に把握して備えておきましょう。
誤引用・AIハルシネーション
AIが存在しない文献や不正確な情報を生成するリスクがあります。出典必須プロンプトの設計と、生成されたURLの実在確認スクリプト(post-validation)で対策します。
robots.txt設定ミス
GPTBotやPerplexityBotを誤ってブロックすると、AI引用が激減します。定期的にrobots.txtログを監査し、AIクローラーのUser-Agentを最新リストと照合しましょう。
著作権侵害リスク
学習データに問題のあるコンテンツが混入すると、生成物が既存作品と類似する可能性があります。DMCA takedownリストを除外し、生成物の類似性チェックツールを導入することで予防します。
個人情報流出
APPIに違反する形で個人データがベクトル化されるリスクがあります。データ前処理の段階でPII(個人識別情報)をハッシュ化・削除し、ベクトル化前の匿名化を徹底します。
規制変更リスク
AI関連の法規制は急速に変化しています。EU AI Actや国内AIガバナンス改正に伴う要件追加に対応するため、法務チームによる半年ごとの規制モニタリングが推奨されます。
| リスク | 影響度 | 対策 |
|---|---|---|
| 誤引用・ハルシネーション | 高 | 出典必須プロンプト + URL実在確認スクリプト |
| robots.txt設定ミス | 高 | 定期監査 + AIクローラーUA最新リスト照合 |
| 著作権侵害 | 中 | 生成物の類似性チェックツール導入 |
| 個人情報流出 | 高 | PII匿名化・ハッシュ化の前処理必須化 |
| 規制変更 | 中 | 半年ごとの規制モニタリング + コンプライアンス更新 |
参考・引用: 生成AIの著作権 - LegalOnTech AI著作権検討会 - 首相官邸 日本のデータ保護法 - Kiteworks
よくある質問(FAQ)
GEOとSEOの違いは何ですか?
SEOは検索エンジンの順位アルゴリズムを対象とし、キーワード順位やオーガニックCTRをKPIとします。GEOは生成AIのRAGとCitation Engineを対象とし、AIの回答に自社コンテンツが引用される確率(Citation Rate)をKPIとします。SEOの上にGEOを「上乗せ」する形で両立させるのが効果的です。
GEOを始めるために最低限必要な施策は何ですか?
まず JSON-LDで FAQPage と Article の構造化データを実装し、各セクション冒頭に40〜50語の結論を配置することから始めましょう。この2つだけでAI引用率は大きく改善します。robots.txtでのAIクローラー許可設定も同時に行うと効果的です。
Perplexityに自社サイトを引用させるにはどうすればいいですか?
robots.txt で User-agent: PerplexityBot を許可し、FAQ形式(「Q. ○○は?」/「A. …」)でコンテンツを記述します。Perplexityは信頼性の高いサイトを優先的に引用するため、E-E-A-T(特に著者情報と更新日)の明示も重要です。Pro Searchモードでは複数ソースを深掘りするため、専門性の高いコンテンツが引用されやすくなります。
日本語コンテンツでもGEOは効果がありますか?
はい、効果があります。特にClaudeは日本語の自然言語処理精度が高く、敬語表現を正しく解釈します。日本語では1文を30〜50トークンに収める短文設計が有効です。hreflang="ja" と locale="ja_JP" の設定も忘れずに行いましょう。日本特有の文化的トピック(和食、温泉など)はAI引用の対象になりやすい傾向があります。
GEOに法的リスクはありますか?
はい、主に3つの領域に注意が必要です。著作権法では、AI生成物が既存作品と「類似性」+「依拠性」を持つ場合に侵害になります。個人情報保護法(APPI)では、ベクトルDB格納前のPII匿名化が必須です。また、AIガバナンスガイドラインでは出典表示と誤情報防止が求められます。法務チームによる定期的なリスク評価を推奨します。
まとめ:GEO導入は構造化データとQ&A形式から始めよう
GEOの基本は3つです。構造化データの整備、Q&A形式のコンテンツ設計、そしてプラットフォームごとの出典要求への対応。この3つを組み合わせることで、AIが自社コンテンツを「引用」する確率を高められます。
まず着手すべきは、フェーズ0(競合のAI引用状況調査)とフェーズ1(JSON-LDとrobots.txt整備)です。この2ステップは1〜2週間で完了でき、Citation Rateの改善を即座に実感できるはずです。その後、コンテンツのAPO化とプラットフォーム連携を段階的に進め、法務・コンプライアンスの体制を整えていきましょう。
GEOの成功にはサイト外でのブランド言及が不可欠です。被リンクよりブランド言及が重要な理由と具体的な施策については「AI検索に選ばれるには「自サイトの外」が9割」で解説しています。
LinkSurgeのAI Overview分析機能では、Google AI OverviewsやChatGPTでの自社ブランドの引用状況をリアルタイムで分析できます。GEO戦略の効果測定ツールとして、ぜひご活用ください。
