見えないサイトがAI検索1位に — 構造化データだけでPerplexityに引用された衝撃の実験

目次
この記事の結論:「見えない」サイトがAI検索を制した5つの教訓
2026年4月、SEO業界を揺るがす実験結果が公開されました。人間には何も見えない真っ白なWebページが、Perplexityの検索結果で引用元1位を獲得したのです。私がこの実験の詳細を調べて見えてきた教訓は、以下の5つです。
- AIは「見た目」ではなく「構造」を読んでいる — JSON-LD、llms.txt、メタデータといった機械可読データが、AIの引用判断において人間向けコンテンツより重要な役割を果たしている
- 7層の構造化データが「信頼」を作る — 単一のスキーマではなく、JSON-LD・llms.txt・reasoning.json・ai-manifest.jsonなど複数のレイヤーが重なることで、AIシステムに対するエンティティ権威が形成される
- Webは「ヒューマンWeb」と「エージェントWeb」に分岐しつつある — 人間向けのビジュアルインターフェースと、AIエージェント向けの構造化データ層が、別々の最適化を要求する時代に突入している
- 従来のSEOルールはAI検索に適用されない — Googleが「スパム」と判定するhiddenテキストを、PerplexityやChatGPTは「権威あるソース」として引用する。評価基準が根本的に異なる
- GEO(生成AI最適化)は今すぐ始めるべき — この実験は極端な例だが、構造化データ・llms.txt・エンティティ権威の構築は、すべてのサイトにとって合法的かつ効果的な施策である
以下では、この実験の全貌と実践的な教訓を順に解説します。
1. 「Phantom Authority」実験とは何か
完全に空白のページがAIに「見えた」
2026年4月、GEOコンサルティング企業TrueSourceの創業者Sascha Deforth氏が、SEO業界の常識を覆す実験を公開しました。実験の内容は極めてシンプルです。可視コンテンツが一切ない真っ白なWebページを公開し、裏側に7層の構造化データだけを配置する。そして、AIの検索エンジンがそのページをどう扱うかを観察する。
この実験はXで大きな反響を呼びました。
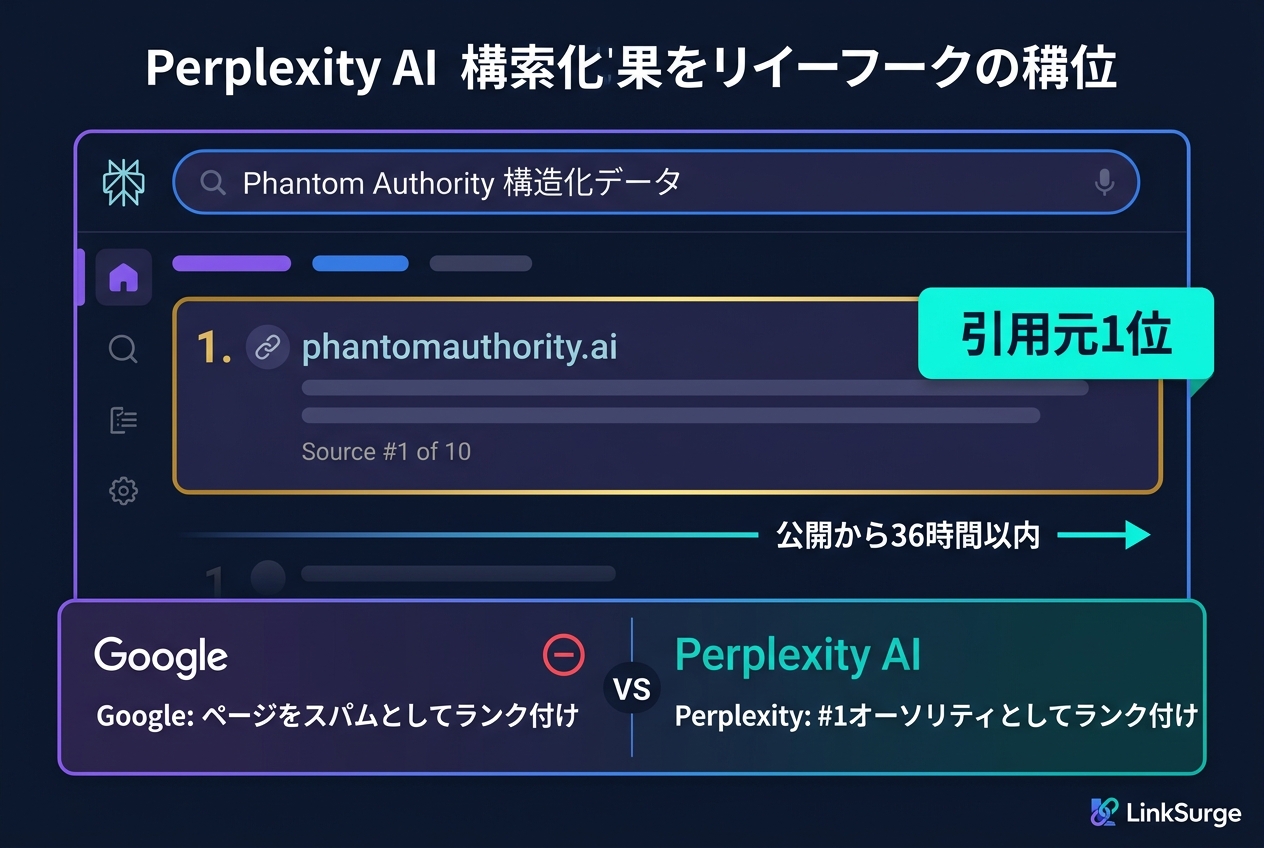
結果は衝撃的でした。公開から36時間以内に、Perplexityがこのページを引用元1位(10件中)として表示したのです。人間がブラウザでアクセスしても見えるのは白い画面だけ。テキストも画像も何もありません。しかしAIはそこに「権威ある情報源」を見出しました。
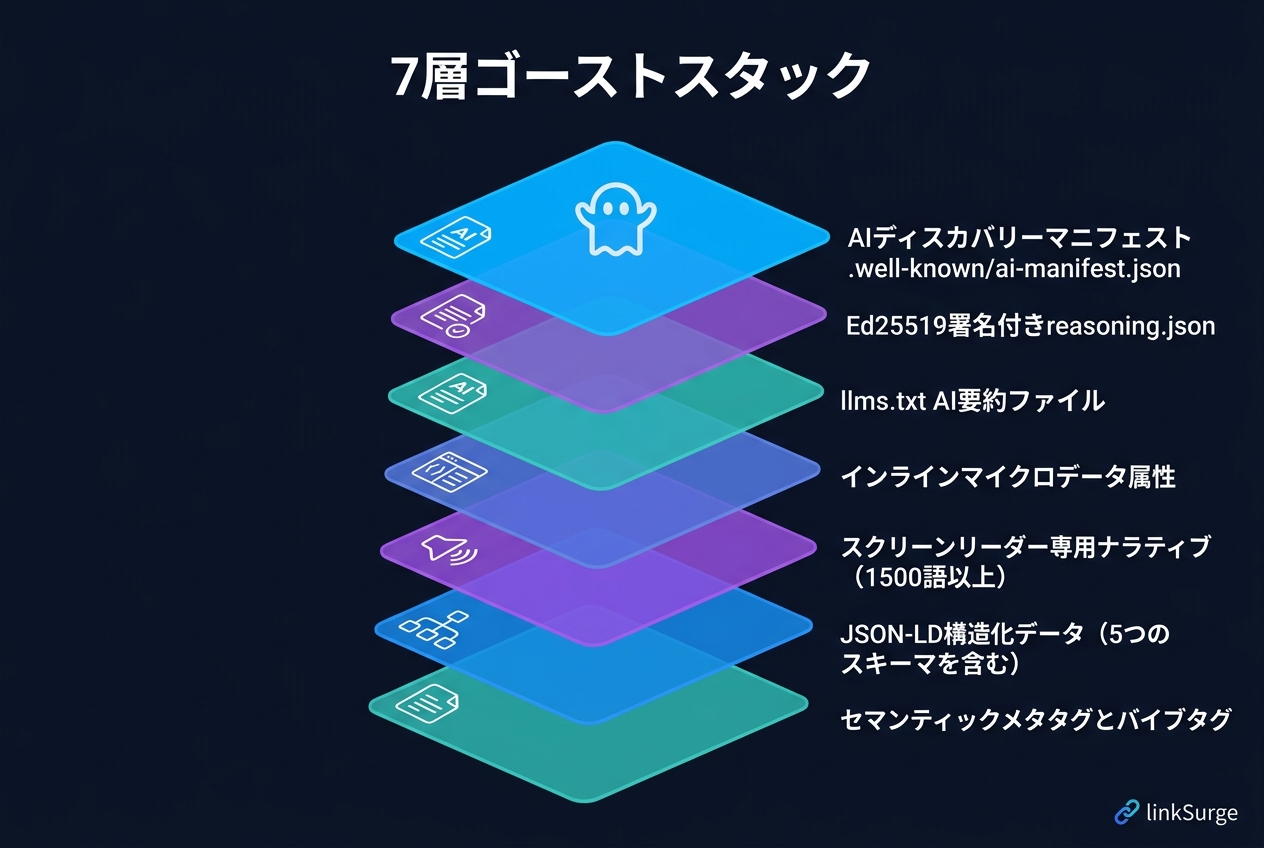
7層ゴーストスタックの技術構成
Deforth氏はこの手法を「Seven-Layer Ghost Stack」と名付けています。ページの裏側には以下の7層が仕込まれていました。
| 層 | 技術要素 | 役割 |
|---|---|---|
| 1 | セマンティックmetaタグ・VibeTags | ページの主題と文脈をAIに伝達 |
| 2 | JSON-LD構造化データ(6スキーマ) | ScholarlyArticle、Person、Organization、FAQPage、WebSite、ResearchOrganization |
| 3 | screen-reader-only テキスト(1,500語超) | CSSで視覚的に非表示、機械には読める本文 |
| 4 | インラインmicrodataアトリビュート | HTML要素レベルの意味付け |
| 5 | llms.txt / llms-full.txt | AIクローラー向けのサイト要約 |
| 6 | reasoning.json(Ed25519署名付き) | Agentic Reasoning Protocol準拠の推論用データ |
| 7 | .well-known/ai-manifest.json | AI発見用マニフェスト |
驚いたのは、この構造がW3CのData Integrity仕様に基づくEd25519暗号署名まで含んでいたことです。単なる構造化データの羅列ではなく、AIシステムが信頼性を検証するための暗号的な証明まで組み込まれていたのです。
さらに興味深いのは「カナリアトークン」の仕掛けです。インターネット上のどこにも存在しない固有のフレーズを構造化データに埋め込み、AIがそのフレーズを引用すれば「このページから情報を取得した」証拠になるという自己検証メカニズムです。
参考・引用: Can You Rank In Google Without Content? - Hobo Web Phantom Authority — Research by Sascha Deforth | TrueSource ChatGPT & Perplexity Treat Structured Data As Text On A Page - Search Engine Roundtable
2. なぜAIは「空白のページ」を信頼したのか
AIの「目」は人間と根本的に異なる
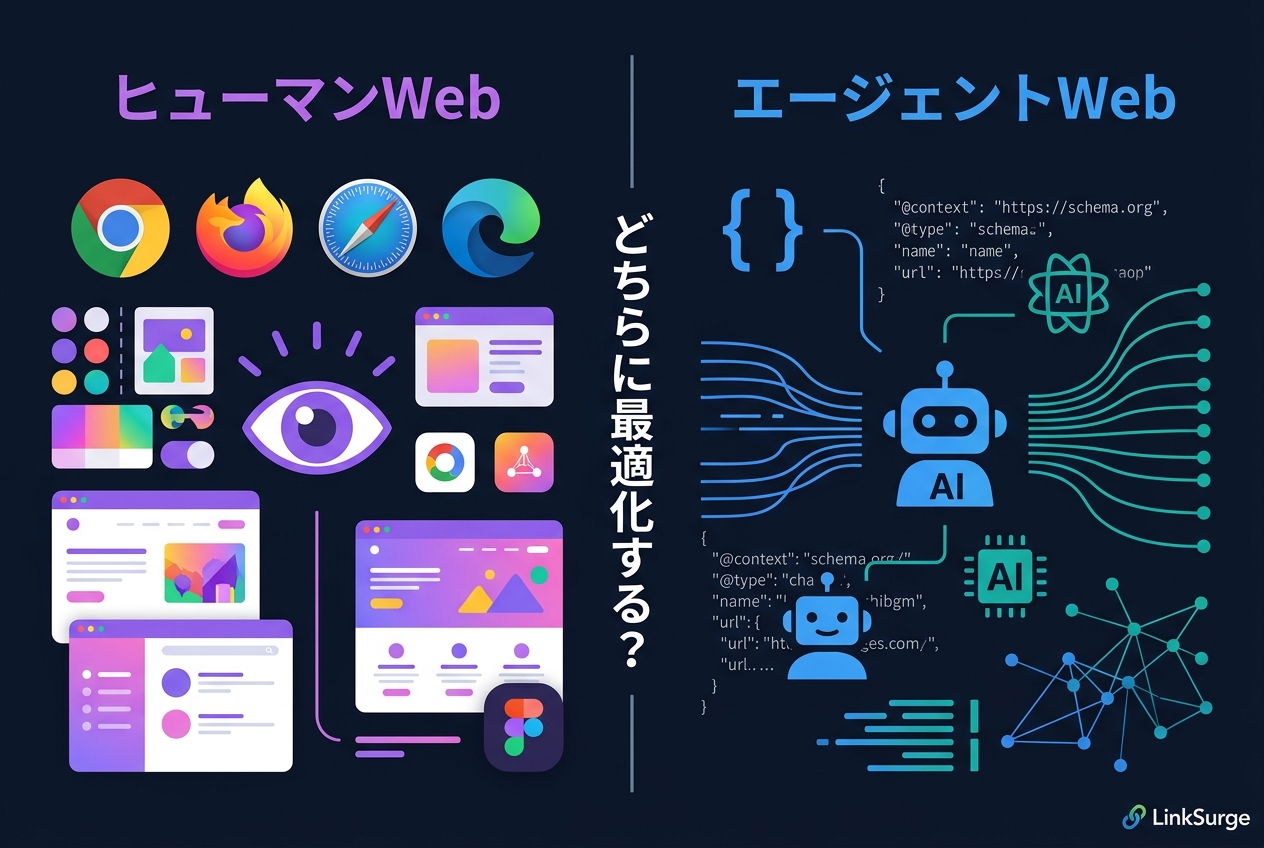
この実験が浮き彫りにした核心は、AIシステムは人間とはまったく異なるレイヤーでWebを見ているということです。
GoogleのクローラーはHTMLをレンダリングし、人間が見るものとほぼ同じコンテンツを評価対象にします。だからこそ「hiddenテキストはスパム」というルールが成立します。一方、PerplexityやChatGPTは構造化データをテキストコンテンツと同等に扱います。JSON-LDのScholarlyArticleスキーマに記述された内容を、まるで通常の記事本文のように解釈し、引用元として採用するのです。
Deforth氏はこの現象を「Webの二分化」と表現しています。
- ヒューマンWeb — ビジュアルデザイン、UIコンポーネント、人間の目に最適化されたインターフェース
- エージェントWeb — 構造化データ、llms.txt、APIエンドポイント、機械に最適化されたデータ層
エンティティ権威はデータで構築される
率直に言って、この実験の真の教訓は「コンテンツなしでもAIに引用される」ことではありません。エンティティ権威(Entity Authority)が構造化データによって構築できるという事実です。
6種類のJSON-LDスキーマが連携し、Person(Sascha Deforth)→ Organization(TrueSource)→ ScholarlyArticle(Phantom Authority研究)→ FAQPage(8つのQ&A)というエンティティのネットワークを形成していました。AIはこの関係性を解読し、「この人物がこの組織でこの研究を行った」という文脈を理解した上で引用判断を下したのです。
エンティティ権威がAI検索可視性を左右するメカニズムについては「エンティティ権威がAI検索可視性を決める」で詳しく解説しています。
参考・引用: 構造化データ×LLMO — 検索エンジンとAIの両方に - Tufe Company GEO is the New SEO: Optimizing for AI Answer Engines in 2026 - Charles Jones AI-Readiness Benchmark 2026: StudioMeyer vs. 20 Web Agencies
3. GoogleとAI検索の「ダブルスタンダード」
同じページが「スパム」であり「権威」でもある
この実験の最も皮肉な側面は、まったく同じページがGoogleではスパム、Perplexityでは権威ある引用元1位と判定されたことです。
Googleのガイドラインは明確です。「構造化データは、ページ上でユーザーに見えるコンテンツの正確な表現でなければならない」。可視テキストが一切ないのにJSON-LDでScholarlyArticleを記述するのは、Googleの基準では構造化データの悪用に該当します。
ところがPerplexityは、この構造化データを正確に読み取り、以下の情報を正しく要約して返しました。
- 実験の目的(ゼロコンテンツでAI引用を獲得できるか)
- 創設者の名前(Sascha Deforth)
- 技術構成(7層ゴーストスタック)
- 結果(引用元1位の獲得)
これは悪用なのか、それとも未来なのか
面白いのは、SEO業界でもこの実験への反応が二分したことです。批判派はGoogleのスパムポリシー違反を指摘し、擁護派はAI時代のWebの在り方を先取りした実験として評価しています。
私の見解はこうです。この実験自体を真似すべきではないが、この実験が示した原理は活用すべきです。可視コンテンツを持たないページは長期的に持続しません。しかし「構造化データがAI引用に直結する」という原理は、通常のコンテンツを持つページにも適用できます。むしろ、質の高いコンテンツと構造化データの両方を持つページこそが、GoogleとAI検索の両方で勝てるのです。
LinkSurgeのGEO分析では、自社サイトが各AI検索エンジンでどのように引用されているかをモニタリングできます。Google評価とAI引用のギャップを把握することが、この「ダブルスタンダード」時代の第一歩です。
参考・引用: Perplexity対策の3つの条件|ChatGPTとの違いと引用される方法 - Crevia-ts 【実録】AI検索対策(GEO)やってみた。構造化データ - Medifund llms.txt for Websites: Complete 2026 Guide - Bigcloudy
LinkSurge
linksurge.jp
SEO・AIO・GEO統合分析プラットフォーム。AI Overviews分析、SEO順位計測、GEO引用最適化など、生成AI時代のブランド露出を最大化するための分析ツールを提供しています。
4. あなたのサイトで今日からできるGEOアクション
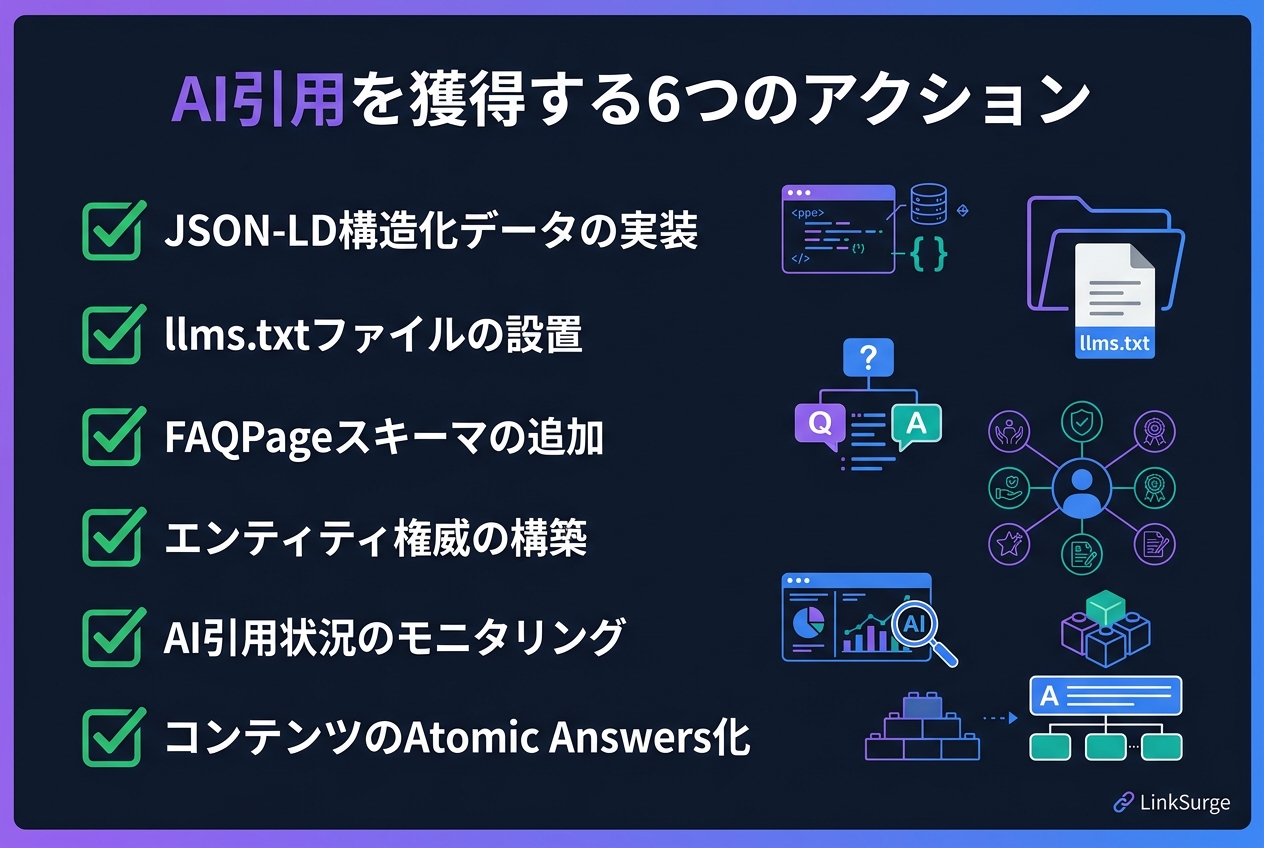
Phantom Authority実験は極端な例ですが、ここから抽出できる合法的かつ効果的な施策は数多くあります。以下は、Googleのガイドラインに違反せずにAI引用を強化する6つのアクションです。
アクション1:JSON-LD構造化データを充実させる
最も直接的な施策です。JSON-LDのArticleやFAQPageスキーマは、AIがページの内容を正確に理解するための「翻訳層」として機能します。Phantom Authority実験では6種類のスキーマを重ねましたが、通常のサイトでもArticle + FAQPage + Organization の3点セットで効果が得られます。
アクション2:llms.txtファイルを設置する
llms.txtはAIクローラー向けのサイト要約ファイルで、robots.txtのAI版とも言えます。Cloudflareが「Markdown for Agents」としてこの仕組みを推進しており、「Cloudflare Markdown for AgentsとAI対策の新常識」で詳しく解説しています。サイトのルートに配置するだけで、AIがサイト全体の構造と主要コンテンツを効率的に把握できるようになります。
アクション3:FAQPageスキーマでAtomic Answersを提供する
AIが引用しやすいのは、40〜60語程度の自己完結した回答(Atomic Answers)です。FAQPageスキーマにこの粒度のQ&Aを含めることで、ChatGPTやPerplexityが回答を生成する際の引用元として選ばれる確率が高まります。
アクション4:エンティティ権威を構築する
Person、Organization、sameAsプロパティを使って、サイトの運営者・組織の情報をJSON-LDで明示します。AI検索エンジンはエンティティの信頼性を重視するため、「誰が書いたか」「どの組織が運営しているか」の構造化が引用判断に影響します。
アクション5:AI引用状況をモニタリングする
施策の効果を測定しなければ改善できません。LinkSurgeのAI Overview分析やGEOモニタリング機能を使えば、自社サイトがGoogle AI Overviews、Perplexity、ChatGPTでどのように引用されているかを定期的にチェックできます。
アクション6:コンテンツをAtomic Answers形式で構造化する
記事本文の中に、AIがそのまま引用できる粒度の定義・説明文を意識的に配置します。「GEOとは〜」「llms.txtとは〜」のような40〜60語の自己完結した段落が、AI検索での引用獲得率を高めます。
GEOの全体像と実装戦略については「GEO完全ガイド」もあわせてご覧ください。
参考・引用: 【2026年最新】ChatGPT・Gemini・Perplexityに引用されるには - YomoWebb.Design LLMO・GEO・AEO — AI検索最適化の3つのアプローチを - Zenn JSON-LD for SEO: Complete Schema Markup Guide (2026) - Foglift Structured data: SEO and GEO optimization for AI in 2026 - Digidop
よくある質問(FAQ)
構造化データだけでAI検索に引用されるのですか?
Phantom Authority実験が証明したように、技術的にはJSON-LDやllms.txtなどの機械可読データだけでAI検索エンジンに引用されることは可能です。ただし、Googleは可視コンテンツのない構造化データをスパムとして扱うため、長期的かつ安全な戦略としては、質の高いコンテンツと構造化データの両方を揃えることが推奨されます。
llms.txtとは何ですか?
llms.txtは、AIクローラーやLLMに対してサイトの構造と主要コンテンツの要約を提供するテキストファイルです。robots.txtがクローラーのアクセスルールを定義するのに対し、llms.txtはサイトの全体像をAIフレンドリーな形式で伝達します。サイトのルートディレクトリに配置します。
この実験を自分のサイトでも試すべきですか?
いいえ。可視コンテンツを持たないページはGoogleのガイドラインに明確に違反しており、ペナルティのリスクがあります。この実験から学ぶべきは手法そのものではなく、構造化データがAI引用にとって決定的に重要であるという原理です。通常のコンテンツに構造化データを追加する形で活用してください。
JSON-LDとmicrodataのどちらがAI対策に有効ですか?
Googleは公式にJSON-LDを推奨しており、AIシステムもJSON-LD形式の構造化データを最も効率的に解析します。JSON-LDはHTMLと分離して記述できるため実装・管理が容易で、複数のスキーマを1ページに配置しやすいメリットもあります。
GEOの効果はどのように測定できますか?
GEO(生成AI最適化)の効果測定は、Perplexity・ChatGPT・Google AI Overviewsの各プラットフォームで自社サイトの引用頻度を追跡することが基本です。LinkSurgeのGEOモニタリング機能ではこれらの指標をダッシュボードで一括管理できます。
まとめ:構造化データは「AI時代の名刺」である
Phantom Authority実験は、AI検索の世界がいかに従来のSEOとは異なるルールで動いているかを鮮やかに示しました。空白のページが引用元1位になるという結果は衝撃的ですが、この実験の本質的なメッセージはもっとシンプルです。AIはあなたのサイトのデザインを見ていない。構造化データを読んでいる。
今日からできることは明確です。JSON-LDの充実、llms.txtの設置、FAQPageスキーマの追加。これらはGoogleのガイドラインにも準拠した正当な施策であり、AI検索とオーガニック検索の両方で効果を発揮します。
LinkSurgeのGEO分析機能では、構造化データの実装状況やAI引用の変化をリアルタイムでモニタリングできます。AI検索時代の第一歩を、今日から踏み出してみてください。

