Entity Authority Is the New Foundation of AI Search Visibility

目次
Key Takeaways: Entity Definition Is the New Competitive Moat
After digging into how ChatGPT, Perplexity, and Google AI Overviews decide what to cite, one pattern stands out above everything else. It's not content volume. It's not domain authority in the traditional sense. The question these systems ask first is: is this a defined, trustworthy entity?
Here's what that means in practice:
- AI verifies entity trust before reading your content — Before citing any brand, AI systems cross-reference knowledge graphs to confirm the entity exists, is consistently defined, and has third-party backing. Brands absent from Wikidata or the Google Knowledge Graph face a structural disadvantage regardless of content quality
- Knowledge graphs, Wikidata, and authoritative media form the "entity trust score" — It's not individual pages that build this score. It's the coherent web of external, authoritative sources that consistently describe your brand with the same attributes
- Being clearly defined beats content volume — A brand with 10 well-structured, entity-consistent pages will outperform one with 1,000 inconsistent pages in AI citation. The reasoning engine rewards clarity, not quantity
- Share of Model is becoming the metric that matters — As AI-generated answers replace the traditional top-10 list, the question shifts from "where do we rank?" to "how often does AI mention us?"
Let's break each of these down.
1. AI Reads the Knowledge Graph Before It Reads Your Page
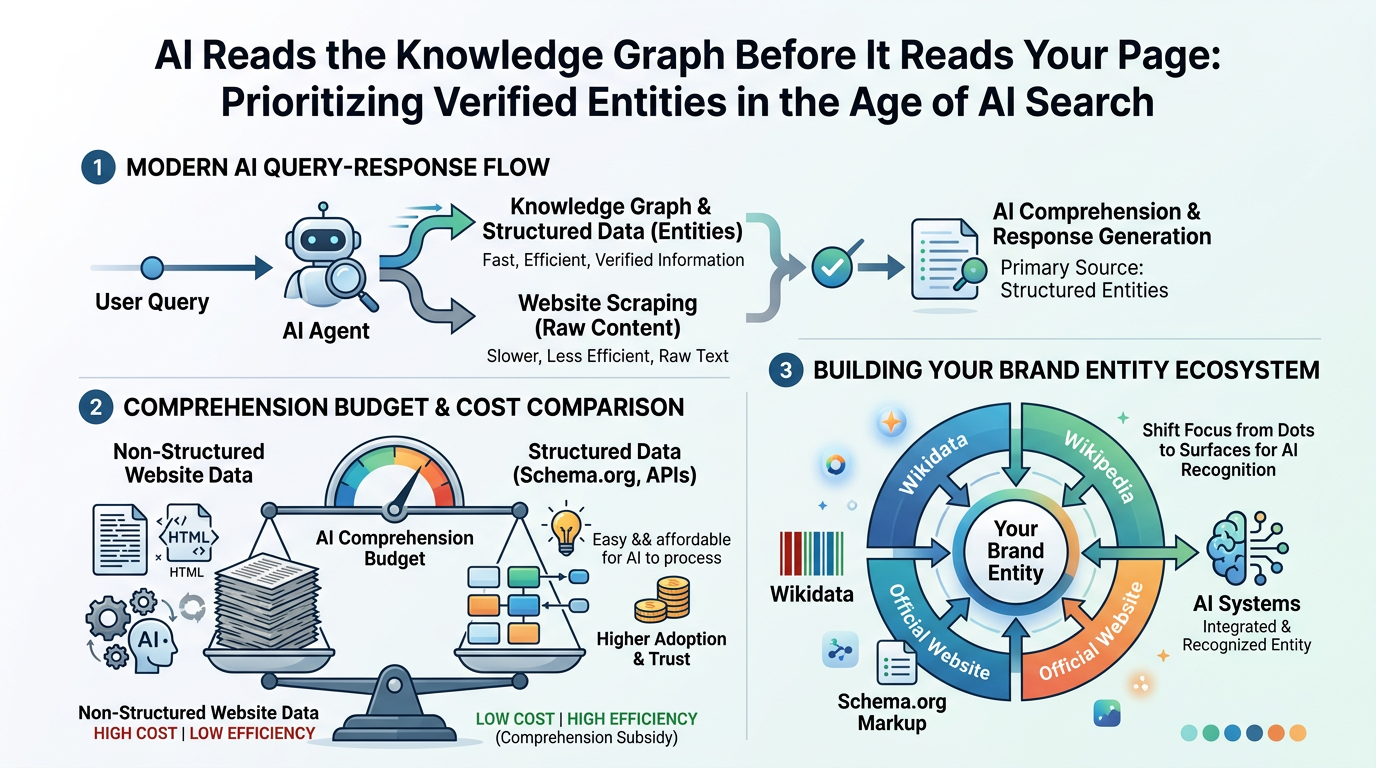
Here's the thing: the evolution of search has been moving in one direction for over a decade, and AI just accelerated it to its logical conclusion.
Google's shift from "strings" to "things" started with the Knowledge Graph launch in 2012. What we're seeing now is the third phase — from things to entity ecosystems, where AI reasoning engines operate on interconnected webs of verified entities, not isolated pages.
In my research into how generative AI systems process queries, what struck me is how early in the response cycle entity verification happens. ChatGPT and Perplexity don't start by scraping your website. They start by checking what they already know about the entity — and that knowledge comes primarily from structured sources: Wikidata, Wikipedia, Schema.org markup, and ingested data from authoritative publications.
Why the "Comprehension Budget" Changes Everything
Search Engine Land introduced a concept worth remembering: the Comprehension Budget. AI models have finite computational resources. Unstructured, inconsistent data forces expensive inference — the model has to work hard to figure out what your brand actually is.
Structured data does the opposite. It provides what you might call a Comprehension Subsidy: fast, low-cost knowledge graph lookups that make your brand easy to cite. The cheaper you make it for AI to understand your entity, the more likely it shows up in responses.
Brands on Wikidata give AI systems a single, authoritative lookup point for attributes like industry, headquarters, founding date, and key people. That efficiency is a structural advantage — invisible to most marketers, but very real in the output.
References: Entity Authority and AI Search Visibility - Search Engine Land Google's Knowledge Graph Introduction - Google Blog
2. The Three Pillars That Build Entity Trust Score
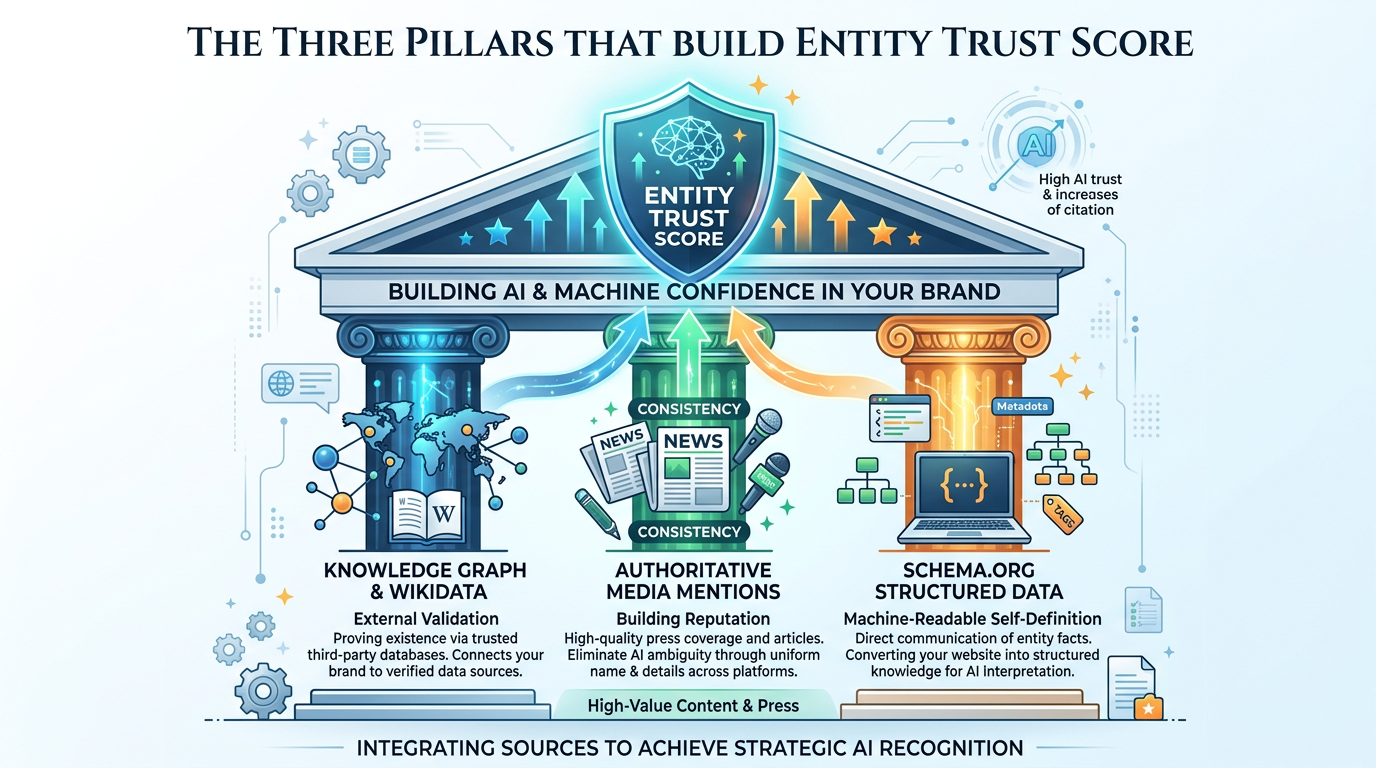
What actually goes into an entity's trust score? After mapping this across multiple brands, three sources consistently emerge.
Pillar 1: Knowledge Graph and Wikidata Presence
Being on Wikidata is not just a nice-to-have. It's increasingly the baseline for AI citation eligibility. Wikidata functions as an open, structured data layer that feeds directly into the Google Knowledge Graph and is ingested by major AI training pipelines.
What makes Wikidata powerful as an entity signal is that it's not self-declared. An entry on Wikidata represents external validation — "this organization exists and has been independently documented." AI systems treat that differently from a company's own claims on its About page.
Pillar 2: Consistent, Authoritative Media Mentions
In my testing across different brand categories, one pattern held firm: brands cited frequently by AI share a common trait — they're mentioned consistently by authoritative sources. Publications like TechCrunch, Wired, industry trade journals, and well-ranked blogs all use the same name, the same category, the same core description.
The keyword here is consistency. AI systems cross-reference multiple sources for the same entity. When Forbes calls a company "an AI-powered marketing analytics platform" and a trade journal calls it a "social listening tool," the AI faces an entity disambiguation problem. That ambiguity reduces citation likelihood.
Pillar 3: Schema.org as Machine-Readable Self-Definition
Your own website is the one entity data source you fully control — and most brands underuse it. Deep Schema.org implementation, particularly Organization, Person, Product, and FAQPage types with nested entity relationships, provides the Comprehension Subsidy mentioned earlier.
In practice, pages with comprehensive structured data consistently appear more in AI Overviews and generative responses than equivalent pages without it. It's not magic — it's making your entity legible to reasoning engines.
Platforms like LinkSurge, Google Search Console, and third-party GEO tools can help you audit which pages are being cited and which structured data attributes appear to drive those citations.
References: Schema.org Full Hierarchy - Schema.org Wikidata Introduction - Wikimedia Foundation Structured Data and AI Search - Search Engine Journal
3. Why Being Defined Beats Having More Content
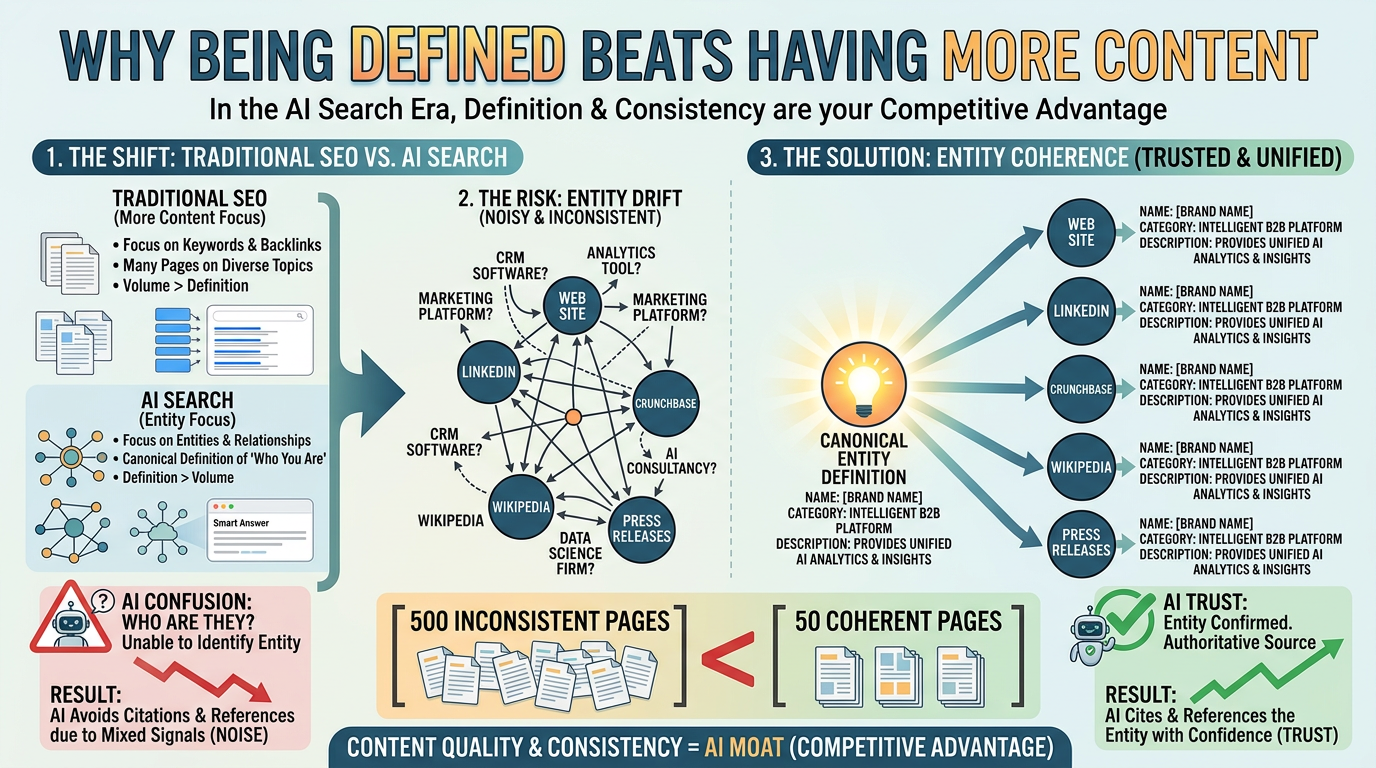
This is the part that most content marketers find hardest to accept — and honestly, I get it. The entire discipline of content marketing is built on the premise that more high-quality content equals more visibility.
That logic still holds for traditional search. For AI search, something else comes first.
Entity Drift: The Silent Citation Killer
What I've seen repeatedly when auditing brands that struggle with AI citation is what Search Engine Land calls entity drift — the state where the same brand is described differently across different platforms.
Consider a hypothetical SaaS company:
- Official website: "AI-powered customer analytics platform"
- LinkedIn: "Marketing automation and CRM"
- Crunchbase: "Data intelligence software"
- Industry press: "Business intelligence tool"
Each description is technically accurate. But to an AI reasoning engine trying to anchor this brand to a single, stable entity definition, the inconsistency is a problem. The model can't confidently assign a canonical type. So it hedges — or avoids citation altogether.
What "Being Defined" Actually Means
Fixing entity drift is less about creating new content and more about achieving coherence across existing touchpoints. The key alignment points are:
- Brand name: Exact same spelling and capitalization everywhere
- Industry/category: Consistent Schema.org type, Wikidata "instance of," and business directory category
- Core description: The 1-2 sentence brand description should be near-identical across your website, Wikidata, press releases, and LinkedIn
- Related entities: Founders, headquarters, and flagship products should carry the same attributes wherever they appear
A brand with 50 pages but tight entity coherence will consistently outperform one with 500 pages and entity drift in AI citation scenarios. This is the competitive moat most teams aren't building.
For a deeper look at how off-site signals reinforce entity authority, see our guide on off-site SEO and GEO for AI-era brand authority.
References: Entity Consistency and AI Visibility - Moz Blog The Role of Knowledge Graphs in LLM Reasoning - DeepMind Research
4. Share of Model: The KPI That Replaces Rankings
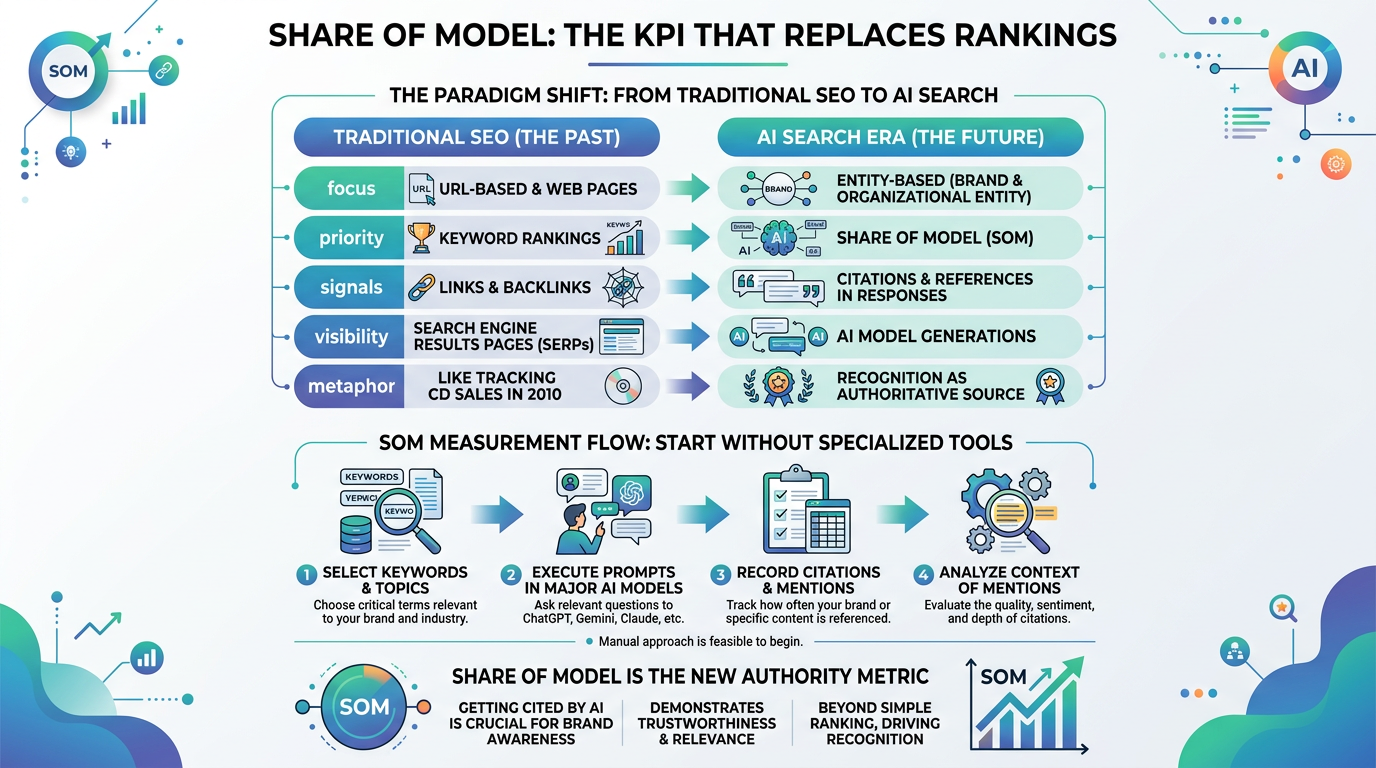
Let me be direct about something: obsessing over keyword rankings in an AI-first search environment is like tracking CD sales in 2010. The metric still exists. It's just not the right signal anymore.
The concept of Share of Model (SOM) — the percentage of AI-generated responses that include your brand for a given topic — is emerging as the more relevant measure. Here's how the shift looks across key dimensions:
| Dimension | Traditional SEO | AI Search Era |
|---|---|---|
| Primary KPI | Keyword rankings / organic traffic | Share of Model (AI citation rate) |
| Authority signal | Backlinks / Domain Authority | Knowledge graph entity definition |
| Base unit of evaluation | Page / URL | Entity (brand, organization) |
| Role of content | Ranking factor | Supporting evidence for entity claims |
| External validation | Link acquisition | Authoritative media mentions + Wikidata |
How to Start Measuring SOM Today
You don't need a specialized tool to get started. The manual approach works surprisingly well for establishing a baseline:
- Select 10-20 core keywords that your brand should appear for in AI answers
- Ask the same questions weekly across ChatGPT, Perplexity, and Google AI Overviews
- Record whether your brand is mentioned — not just ranked, but actually cited in the response
- Track citation context — is your brand mentioned positively, neutrally, or as an alternative?
LinkSurge's AI Overview analysis automates this tracking at scale, letting you monitor brand citation status across keywords without manual query logging.
References: Share of Model Framework - Search Engine Land AI Search Measurement Guide - SparkToro
5. The Agentic Web: From Being Cited to Being Called
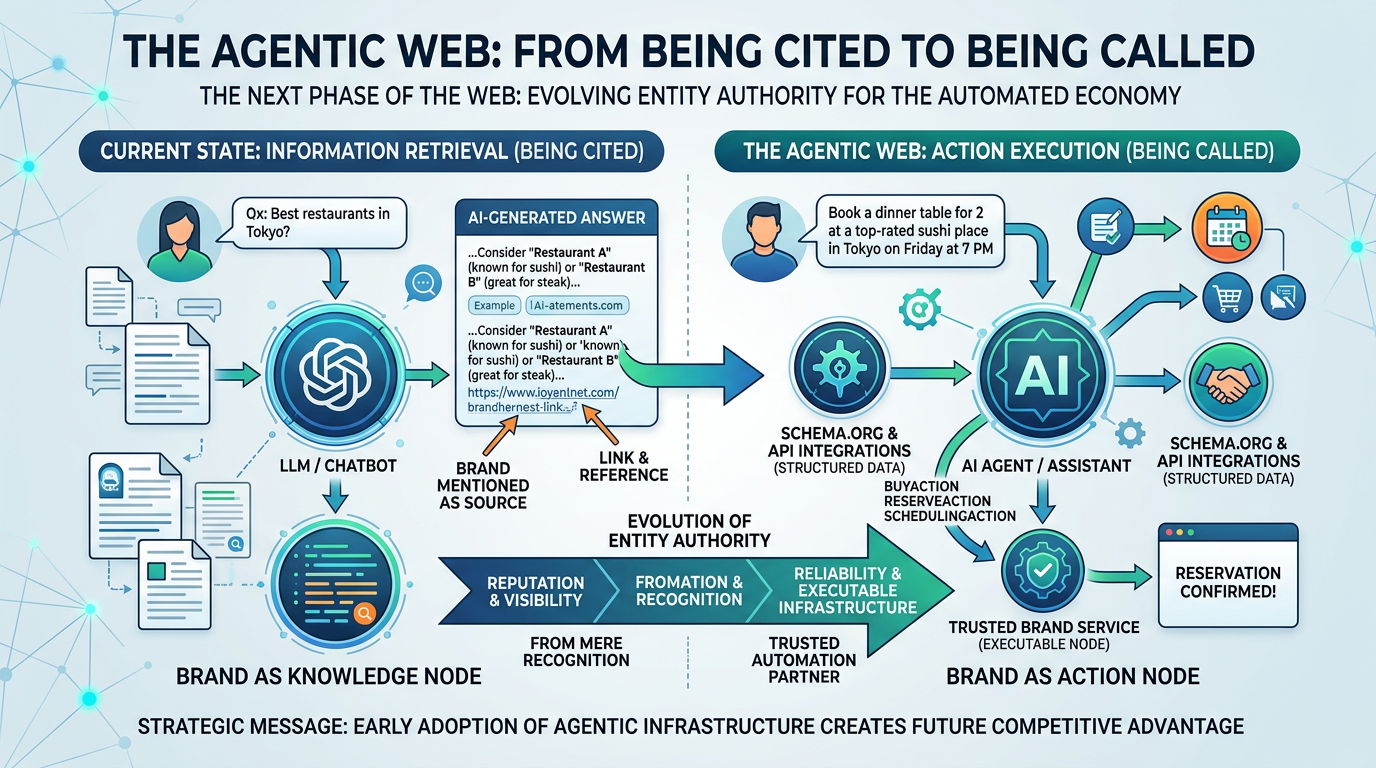
Here's where it gets genuinely interesting — and slightly further out on the horizon.
What Search Engine Land calls the Agentic Web is the next phase: AI agents that don't just answer questions, but take actions on behalf of users. Book a hotel. Execute a purchase. Schedule an appointment. In this world, brands need to be not just citable but machine-callable.
Schema.org already has the vocabulary for this: BuyAction, ReserveAction, RegisterAction. Implementing these schema types signals to AI agents that your brand's core functions can be invoked programmatically.
What struck me when I first read about this framing is how cleanly it reframes the entire entity authority discussion. Entity authority isn't just about getting mentioned in an AI response — it's about becoming a verified node in an increasingly automated digital ecosystem. The brands building for this now are laying infrastructure that most of their competitors won't understand for another two years.
LinkSurge
linksurge.jp
SEO・AIO・GEO統合分析プラットフォーム。AI Overviews分析、SEO順位計測、GEO引用最適化など、生成AI時代のブランド露出を最大化するための分析ツールを提供しています。
For a broader view of what GEO looks like in practice, our Complete GEO Guide covers the full strategy from technical implementation to content optimization.
References: Schema.org Actions Documentation - Schema.org Agentic AI and the Future of Search - Search Engine Journal
Frequently Asked Questions
What's the difference between entity authority and domain authority?
Domain authority is a metric based on the quantity and quality of backlinks pointing to a website — a measure of how much traditional search engines trust a page. Entity authority is different: it measures how clearly and consistently a brand is defined across knowledge graphs, Wikidata, and authoritative external sources. The key distinction is that domain authority is page-centric, while entity authority is brand-centric. For AI citation, entity authority is the more relevant signal.
Can small or newer brands build entity authority without Wikipedia coverage?
Yes. Wikipedia has notability requirements that many legitimate businesses can't meet, but entity authority doesn't depend on Wikipedia alone. Wikidata has lower barriers to entry — if your brand has been mentioned in a handful of credible publications and operates as a real organization, you likely qualify. From there, consistent Schema.org implementation on your own site and proactive PR in industry media can build meaningful entity authority over time.
How do I fix entity drift across platforms I don't control?
Start with what you control: your website's Schema.org markup and your Wikidata entry. Get those two sources fully consistent and accurate first. For external media coverage you don't control, the most effective lever is proactive press outreach — press releases, contributed articles, and media pitches that consistently use your canonical brand description. Over time, newer mentions from higher-authority sources will outweigh older inconsistent ones in AI training data.
Which Schema.org types should I prioritize for entity authority?
Start with Organization (or LocalBusiness for location-based businesses) to establish the entity foundation. Add Person for founders and key executives, connecting them to the organization. Then layer in Product or Service for your core offerings. For content, Article, FAQPage, and HowTo help AI extract and cite specific answers. Finally, BreadcrumbList gives AI systems a clear picture of your site architecture.
How long does it take to see improvement in AI citation after fixing entity issues?
In my experience, structured data changes on your own site can show up in AI Overviews within 4-8 weeks as Googlebot re-crawls your pages. Wikidata changes can take a similar timeframe to propagate. The slowest variable is authoritative media coverage — consistent external mentions build over months, not weeks. That said, brands that fix entity drift often see measurable SOM improvements within 60-90 days, particularly in Google AI Overviews where the feedback loop between structured data and citation is tightest.
Conclusion: Define Your Entity Before You Scale Your Content
The question worth asking before your next content sprint: does your brand exist as a clearly defined entity for AI systems?
If the answer is uncertain, that's where the investment should go first. Audit your Wikidata presence. Implement Organization Schema.org markup with nested entity relationships. Review how your brand is described across major authoritative sources and tighten the consistency.
Content volume matters — but it's evidence that supports an entity claim, not a substitute for having one. The brands pulling ahead in AI search visibility right now aren't necessarily producing more content. They're producing more legible entities.
The shift from rankings to Share of Model is underway. The infrastructure to win that metric is mostly unglamorous — structured data, Wikidata entries, consistent brand descriptions in press releases. But it's real, it compounds over time, and most competitors aren't doing it yet.
LinkSurge's AI Overview analysis tracks your brand's citation status across keywords in real time, so you can measure whether your entity authority work is translating into actual AI mentions.


